머신러닝, 딥러닝에서 굉장히 중요한 역할을 하는 optimizer가 있다. 머신러닝 모델은 굉장히 복잡하기 때문에 앞서 언급한 loss function 혹은 cost function이 최소가 되는 지점을 찾는 것이 쉽지 않다. 최솟값을 찾아가는 과정을 최적화(Optimization)라고 부른다. 이를 수행하는 알고리즘을 학습 알고리즘이라고 한다. 이러한 이유로 학습 알고리즘(Optimizer)을 사용한다.
대부분의 학습 알고리즘의 방법은 미분을 통해서 gradient를 구한 후 해당 방향의 반대 방향(음수)으로 점진적으로 나아가 최적확사 되는 값을 찾는 형태이다. 대표적으로 경사하강법(Gradient Descent)과 역전파(Backpropgation) 알고리즘이 존재한다.
옵티마이저는 굉장히 많다. 요즘은 Adam 하고 활성화 함수로 Relu가 많이 쓰인다고 한다. 나도 대회에 나갔을때 Adam과 활성화 함수로 Sigmoid를 사용했었다. Adam의 성능이 절대적인 건 아니고 데이터와 프로젝트에 따라서 성능이 더 좋은 optimizer가 존재할 수 있다.
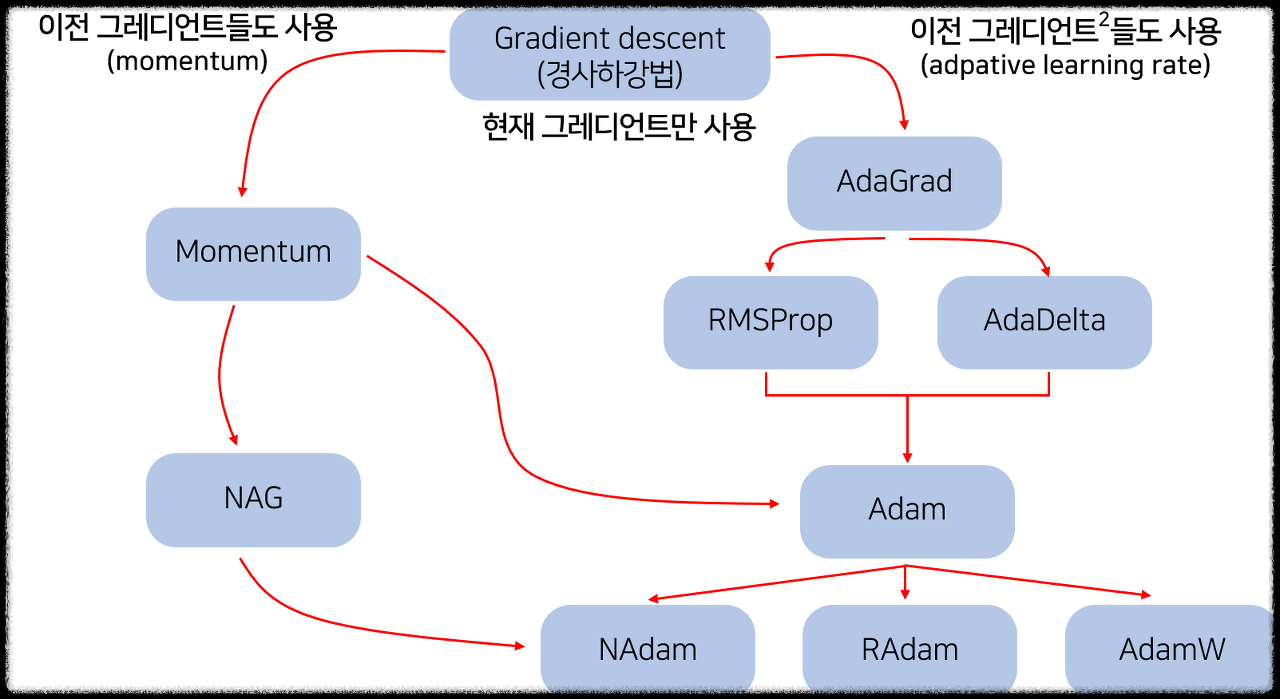
위처럼 다양한 종류의 Optimizer들이 있다. 기본이 되는 Gradient Descent 부터 정리해 본다.
<경사하강법(Gradient Descent)>
<기울기(Gradient)>
기울기란 미분가능한 N개의 다변수 함수를 각 축이 가리키는 방향마다 편미분 한것이다.
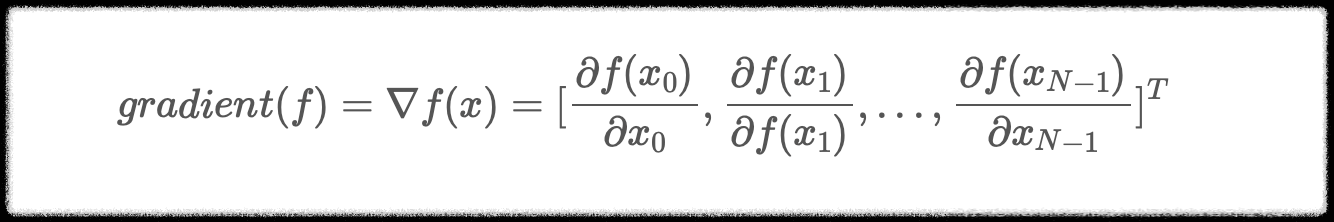
위 식을 풀어보면 x0, x1... xn-1까지의 각 x값을 제외한 나머지를 상수 취급하고 편미분 한다.
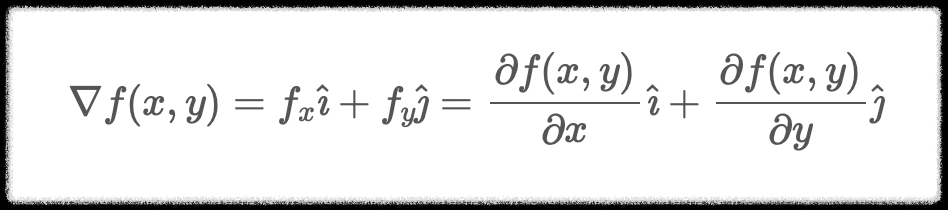
이처럼 Gradient는 스칼라 함수를 입력으로 받아서 벡터장(Vector Field)을 생성하는 역할을 한다.
직관적 이해를 위해서 예시를 들어본다.

Gradient(f)는 x, y의 함수이다. 또한 모든 x, y축에 대응되는 벡터를 생성할 수 있다는 것을 알 수 있다.
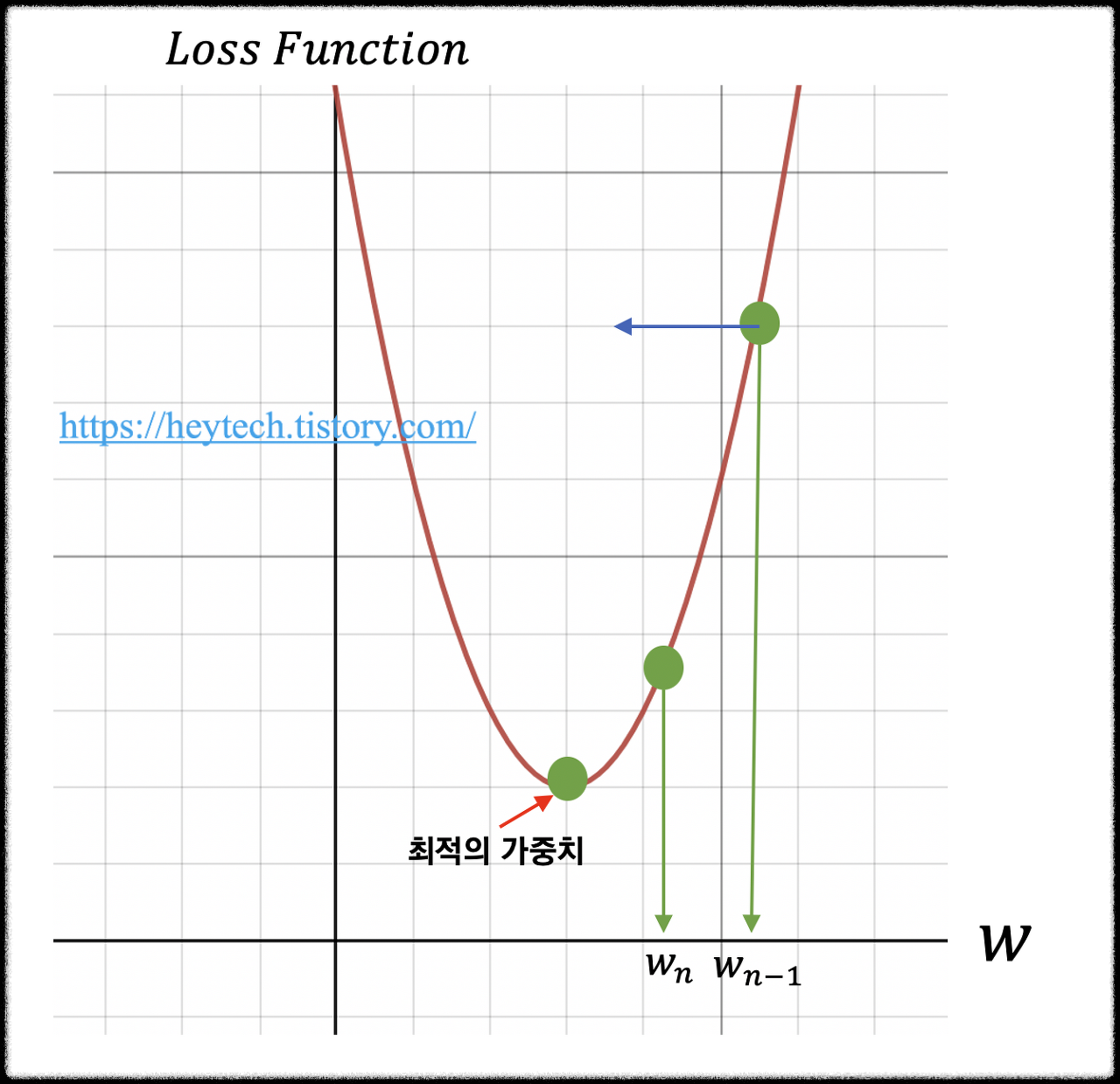
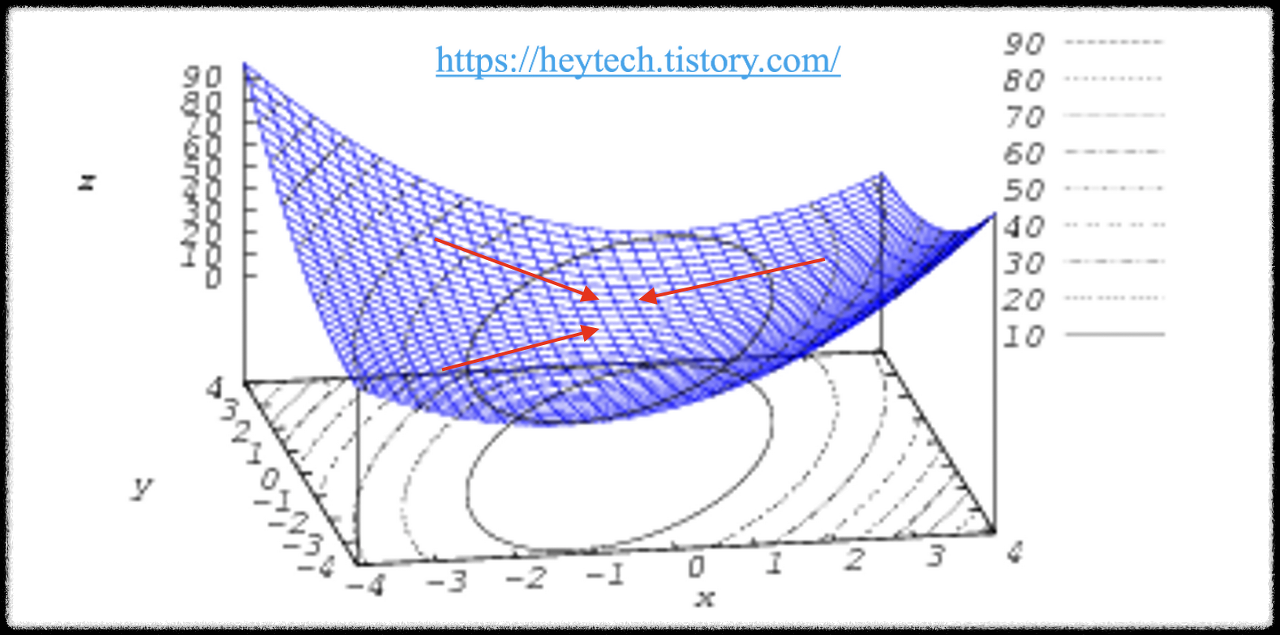
위 그림에서 가로축은 가중치를 의미하고, 세로축은 손실 함수를 의미한다. 손실함수가 최소가 되는 가중치를 찾는 것이 목표다. 딥러닝 알고리즘 학습 시 학습 데이터의 입력을 변경할 수 없기 때문에 손실함숫값의 변화에 따라서 가중치를 업데이트해야 한다.
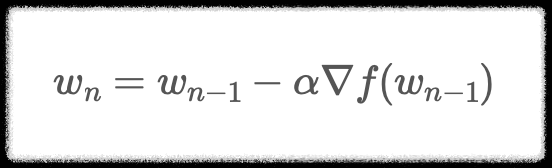
wn-1을 임의의 가중치 즉 시작시점으로 선정했다고 가정한다. 최적의 가중치를 찾기 위해서는 목표 함수인 손실 함수를 비용함수 w에 대해서 편미분 하고 이를 학습률(learning rate)과 곱한 값을 앞서 선정한 wn-1에서 빼준다. 위 수식을 통해서 손실함수의 값이 거의 변하지 않을 때(대략 10^-6)까지 가중치를 업데이트하는 과정을 반복한다. 이 처럼 경사를 타고 하강하는 방법을 경사 하강법이라고 한다.
그러나 이러한 경사하강법은 문제가 있다.
1. local minimun에 빠질 수 있다.
2. Saddle Point에서 벗어나지 못한다.
<Local Minimun>
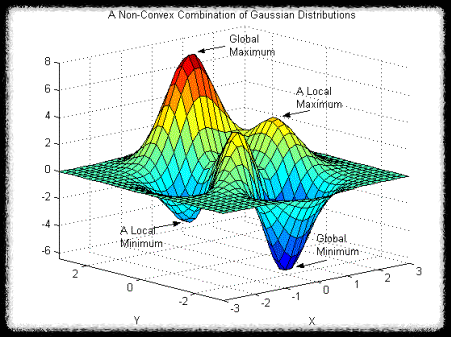
위와 같은 왼쪽 그림을 보면 볼록함수에서는 초기 파라미터 어떻게 설정되어도 경사하강법을 활용하면 최적의 값에 도달할 수 있다. 기울기가 0으로 수렴하는 부분이 하나라서 그렇다. 그러나 오른쪽 그림을 보면 미분값이 0에 수렴하는 지점이 여러 개다. global minimum에 도달하는 것이 목표인데 파라미터의 시작위치에 따라서 local minimum에 도달할 수 있다.

<Saddle Point>
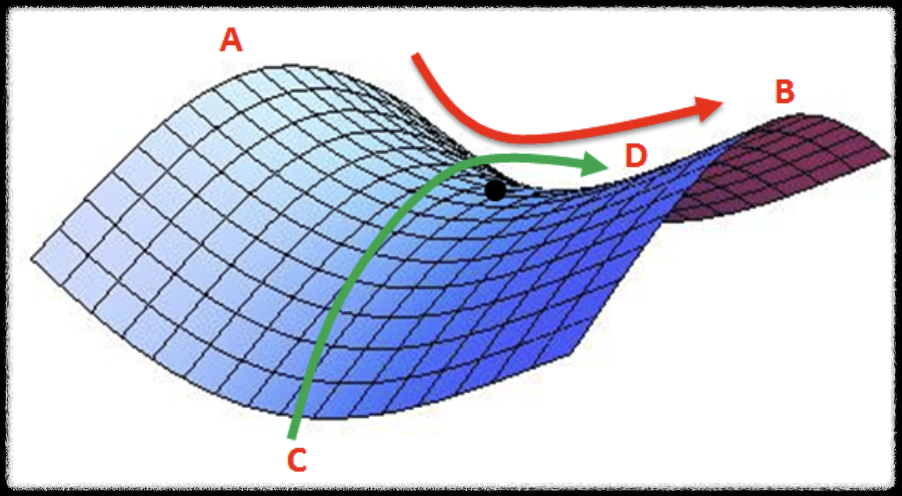
위의 그림처럼 두 번째 한계점은 안장점(Saddle Point)에서 벗어나지 못한다는 것이다. 위 그림은 말의 안장과 비슷한 모양을 가진다. Saddle Point는 기울기가 0이지만 극값이 아닌 지점을 의미한다. A-B 사이에서 검은색점은 최솟값이지만 C-D에서는 최댓값이다. 해당지점은 미분값이 0이지만 극값을 갖지 못한다. 경사하강법에서는 미분값이 0에 근사할 경우 더 이상 파라미터를 업데이트하지 않기 때문에 안장점을 벗어나지 못하는 문제점이 존재한다.
출처: https://heytech.tistory.com/380
[Deep Learning] 최적화 개념과 경사 하강법(Gradient Descent)
📚 목차 1. 최적화 개념 2. 기울기 개념 3. 경사 하강법 개념 4. 경사 하강법의 한계 1. 최적화 개념 딥러닝 분야에서 최적화(Optimization)란 손실 함수(Loss Function) 값을 최소화하는 파라미터를 구하는
heytech.tistory.com
# 경사 하강법 구현(implementation)
import numpy as np
x = 2 * np.random.rand(100,1) # 100 x 1 크기의 0~1의 균일분포
x_b = np.c_[np.ones((100,1)),x] # bias(1)를 전체 데이터에 추가
y = 4 + 3*np.random.randn(100,1) # 100 x 1 크기의 표준정규분포 추출
learning_rate = 0.001
iterations = 1000
m = x_b.shape[0] # 100개 (x 데이터)
theta = np.random.randn(2,1) # 2x1 크기의 평균 0, 분산1 정규 분포 추출
for iteration in range(iterations):
gradients = 2/m * x_b.T.dot(x_b.dot(theta)-y)
theta = theta - (learning_rate * gradients)
print(theta)
# 확률적 경사 하강법 구현(implementation)
epochs = 1000
t0,t1 = 5,50 # 학습 스케쥴 (하이퍼 파라미터)
m = x_b.shape[0] # 100개 (x 데이터)
def learning_schedule(t):
return t0 / (t+t1)
theta = np.random.randn(2,1) # 2x1 크기의 평균 0, 분산1 정규 분포 추출
for epoch in range(epochs):
for i in range(m):
random_index = np.random.randint(m) # 0 ~ m-1까지 랜덤 숫자 1
xi = x_b[random_index:random_index:+1] # 1 x 2 크기
yi = y[random_index:random_index+1] # 1 x 1 크기
gradients = 2 * xi.T.dot(xi.dot(theta)-yi) # 1 => mini_m
learning_rate = learning_schedule(epoch*m + i)
theta = theta - learning_rate * gradients
출처: https://velog.io/@changhtun1/python-선형-회귀-이론-및-실습
[Python] 선형 회귀 이론 및 실습
하나 이상의 특성과 연속적인 타깃 변수 사이의 관계를 모델링 하는 선형 회귀에 대해 파헤쳐보자!
velog.io
<Adam>
Adam은 널리 사용되는 Optimizer의 한 종류다. Adam (Adaptive Moment Esimation) 이러한 이름을 갖고 있다. "적응형 모멘트 판단"이라는 뜻인데 Momentum 기법과 RMSProp 두 가지를 섞어서 만들었다. 진행하던 속도에 관성을 주고 최근 경로에서 곡면의 변화량에 따른 적응적 학습률을 갖는 알고리즘이다.
해당 옵티마이저의 장점은 매우 넓은 범위에서 활용이 가능하다는 것이고, Bounded Step Size를 갖는다는 것이다. Momentum 방식과 유사하게 지금까지 계산해 온 기울기의 지수 평균을 저장하고 RMSProp과 유사하게 기울기의 제곱의 지수평균을 저장한다.
아래의 식을 참고한다.
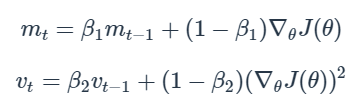
위의 값들을 참고하여서 step 변화량을 조절한다.
m, v가 0으로 초기화되어 있기 때문에 학습 초반에는 mt, vt, mt*vt 가 0에 가깝게 편향되어 있다고 판단하기 때문에 해당 값을 보정해 준다.
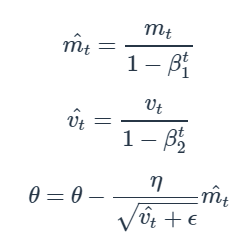

Hyper Parameter는 추천되는 값들이 존재한다.
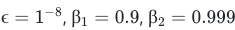
보통 다른 변수들은 고정시키고 에타(η) 값을 수정해 가면서 최적값을 찾는다고 한다.
출처: https://velog.io/@freesky/Optimizer
[딥러닝] 옵티마이저(Optimizer)
딥러닝에 이용되는 Optimizer 는 대부분 Adam 을 쓰고 있다. ..딥러닝 은 입력층과 출력층 사이에 여러 개의 은닉층으로 이루어진 신경망이다.층이 깊어질수록 모듈과 함수에 따른 하이퍼파라미터...
velog.io
각 옵티마이저들의 성능을 비교한 글도 있다.
https://velog.io/@hyunicecream/4가지-옵티마이저에-따른-성능평가-비교Adam-vs-Nadam-vs-RMSProp-vs-SGD
4가지 옵티마이저에 따른 성능평가 비교 Adam vs Nadam vs RMSProp vs SGD
최근에 감성분석이 하고 싶어 해보았는데, 많은 사람들이 각기 다른 Optimizers를 사용하여 각각의 Optimizer결과가 어떻게 다르게 나오는지 궁금하게 되어 시작하였습니다.그래서 이번에 많은 사람
velog.io
물론 프로젝트, 데이터의 종류에 따라 더 잘 맞는 옵티마이저가 있기 때문에 정답은 없다.
본인의 상황에 맞게 여러 가지 시도를 해보는 게 중요하다.
'AI & Data Science > LG Aimers' 카테고리의 다른 글
| 3. 지도학습(회귀,분류) - 4. Least-Squares, Normal Equation (0) | 2023.01.14 |
|---|---|
| 3. 지도학습(회귀,분류) - 2. Hypothesis, Cost Function (0) | 2023.01.14 |
| 3. 지도학습(회귀,분류) - 1. linear Regression, Bias, Variance, Drop out (1) | 2023.01.14 |
| LG Aimers 선정 & 수료 (0) | 2022.12.26 |



