머신러닝은 크게 3가지로 구분 가능하다.
1. 지도 학습
2. 비지도 학습
3. 강화 학습
<지도 학습>
지도학습이란 정답을 알려주고 학습시키는 머신러닝 학습 방법이다.
입, 출력 데이터를 포함한 훈련데이터가 존재하고 새로운 데이터에 대한 출력을 예측한다.
이때 여러 데이터에 대해 여러 개의 값 중 하나를 도출해 내는 분류와 데이터 분석을 특징을 통해 답을 찾아내는 회귀가 있다.
분류는 데이터 군집화를 통해서 데이터가 속해있는 군집을 찾고 분류하고, 회귀는 통계적 방법으로 찾는다.
<분류>
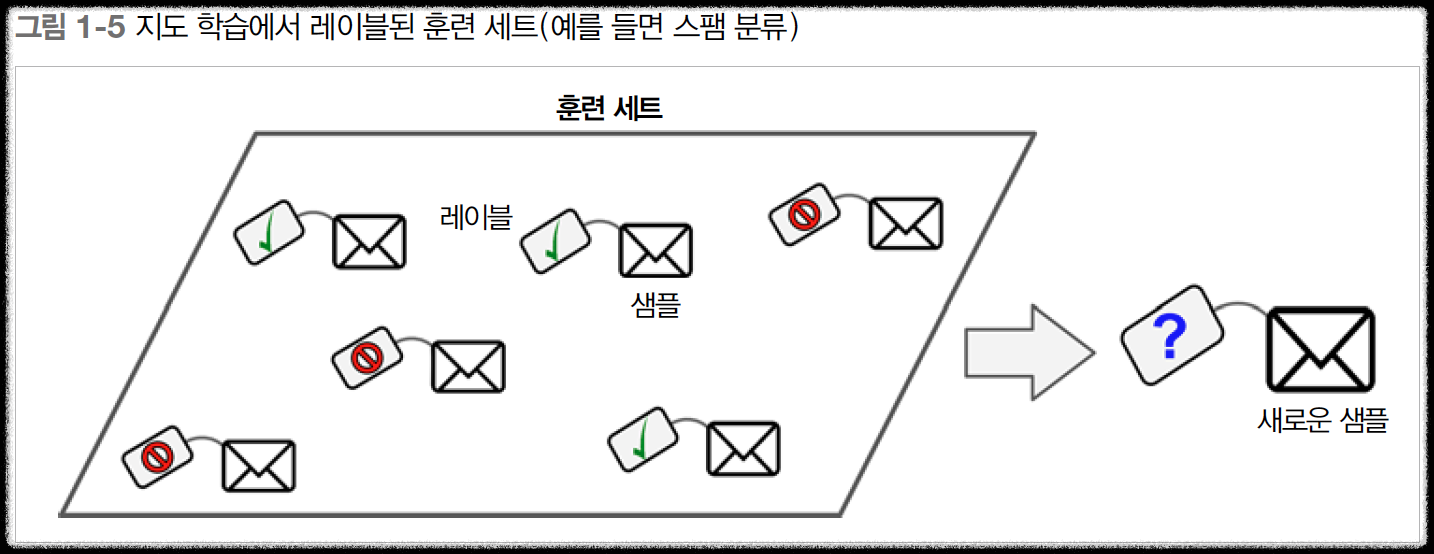
분류는 이중 분류와 다중 분류 문제가 있다. 이중 분류 문제는 보통 참/거짓으로 생각하면 되고 다중분류는 여러 개의 분류 중 하나를 고르는 것이다. 결론적으로 분류 문제는 예측 결과 값이 연속적이지 않고 이산값(discrete)이다.
<회귀>

회귀는 어떤 데이터들의 특징을 토대로 값을 예측하는 것, 종속 변수가 수치형이다(float), 회귀를 통해 확률을 예측한다. 예측결괏값이 이산적이지 않고 연속성이 있는 경우 회귀문제다.
사실 분류도 엄밀히 말하면 각각 class의 대한 확률을 예측하는것이라서 회귀와 종종 헷갈릴 때가 있다.
10년간의 경기도 용인시의 집값 데이터로 1년후 집값을 예측해 보는 건 회귀문제라고 볼 수 있다.(물론 이것은 아주 추상적인 얘기이다.)
다른 블로그에서 분류와 회귀를 구분하는 아주 좋은 예제가 있어서 가져왔다.
분류와 회귀 구분하기
< text가 욕설인지 아닌지 예측하는 문제 >
분류
욕설 데이터와 욕설이 아닌 데이터를 수집하여 모델링하고, 각각의 class에 대한 확률을 예측
-- 이런 개xx xx 하고 있네 - 욕설
-- 댓글 좀 달아주세요 - 정상
회귀 - 잘못된 모델링
- 욕설에 대한 데이터만을 수집하고, 입력이 욕설일 확률을 계산 (출력이 확률이므로 회귀라고 착각)
이것은 학습데이터에서 관측된 feature이 들 입력 text에서 발견되면 score를 높여가는(실제로는 확률도 아니다) scoring 방법이다.
이 경우, 최종 score가 일정 범위 안으로 정규화되기 힘들다.
- 입력의 다양성에 의해 최종 score가 얼마인지 알 수 없다 : 최대 최소 정규화(min-max normalization)를 할 수 없다
- 즉, 0~1 사이로 정규화할 수 없다
- 그런데 꾸역꾸역 여기에 sigmoid나, relu를 붙여 정규화를 했다 치자. (relu, sigmoid의 역할이 아닌데도..)
결국 score가 얼마 이상일 때, 이것을 욕설로 예측한다라는 한계점을 결정해야 하는 문제가 남는다. (relu나 sigmoid에게 맡기려 해도 최댓값을 모르므로 어느 정도가 1을 넘는지 알 수 없다)
그리고 임의로 0.7점 이상이라면 욕설로 볼 수 있다라는 지극히 주관적이고 정성적인 판단을 한다. 여기에 평가셋을 붙여 90% 이상의 정확도라고 말한다. 이렇게 "분류"를 한다고 말한다...
그러다가 학습데이터가 갑자기 늘어났다. 이제 0.7이라는 한계점 더 이상 사용할 수 없다.
회귀는 확률을 예측하는 것이 아니다.
회귀는 출력에 연속성이 있고, 그 연속성 중에 어디에 점을 찍을지 결정하는 문제이다.
출처: https://velog.io/@hyesoup/머신러닝-지도학습과-분류-회귀-예측
분류와 회귀 둘다 본질적으로는 확률을 구하는 것이지만 이것은 수단일 뿐이다.
또 다른 참고글
https://opentutorials.org/module/4916/28942
회귀 VS 분류 - Machine learning 1
지도학습은 크게 ‘회귀’와 ‘분류’로 나뉩니다. 회귀는 영어로 Regression이고, 분류는 Classification입니다. 와!! 말이 정말 어렵죠. 걱정 마세요. 알고 보면 하나도 안 어렵습니다. 그전에 아래 그
opentutorials.org
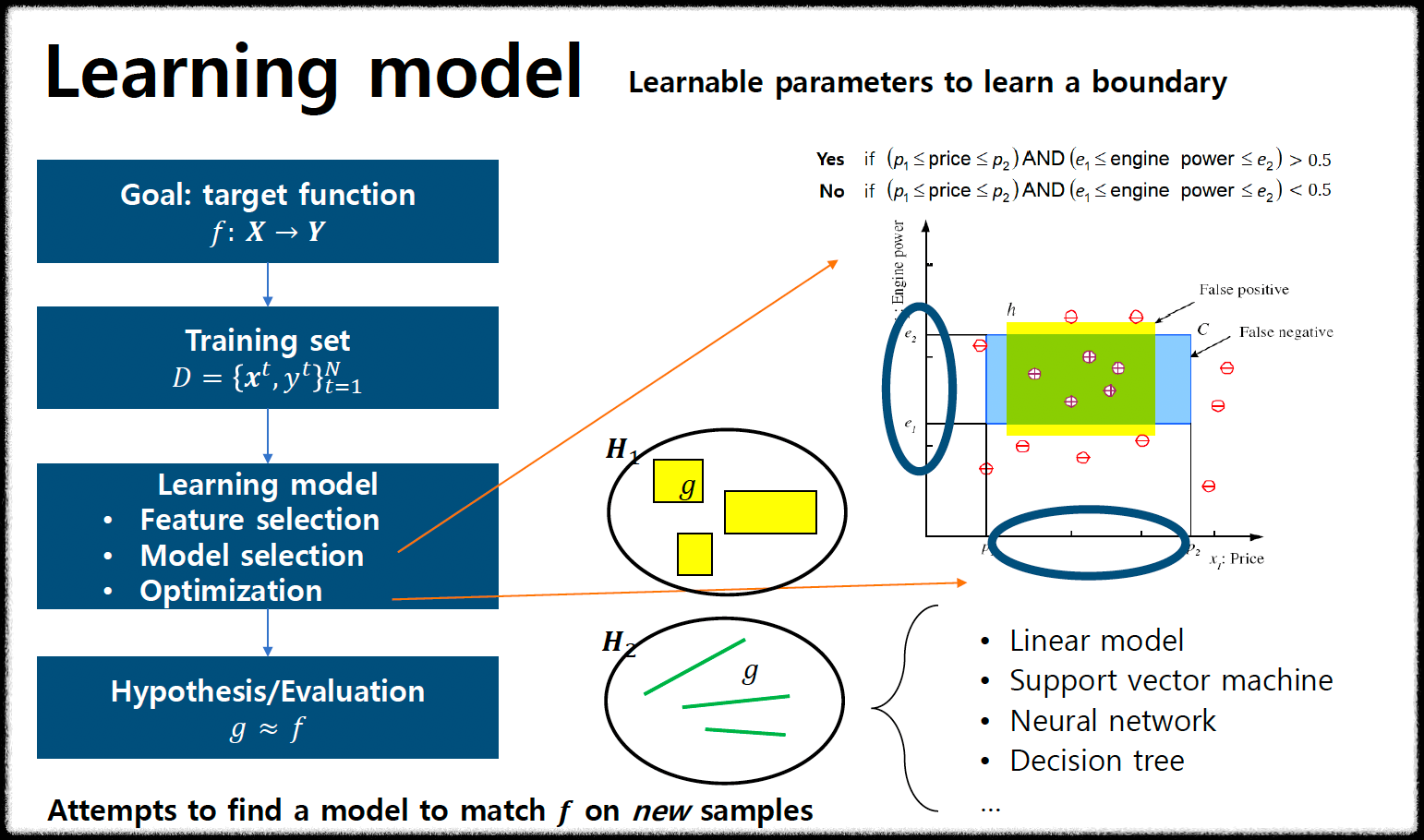
위 사진을 보면 목표는 target function을 제작하는 것이다. 우리는 지도 학습을 공부하고 있기 때문에 Training Set이 필요하다.
일반적으로 xt는 입력값, yt는 출력값을 의미한다. 해당 데이터로 적합한 모델을 만들기 위해서는 특징 선택, 모델 선택, optimization을 거쳐야 한다.
<Linear Regression>
그래서 선형회귀가 뭔지 정의할 필요가 있다. 수학적인 표현을 써보면 어떤 변수의 값에 따라서 특정 변수의 값이 영향을 받고 있는 상황이 있을 수 있다. 운동 시간과 몸무게의 상관관계, 흡연과 음주량에 따른 수명 등등. 다른 변수의 값을 변하게 하는 변수를 x, 변수 x에 의해서 값이 종속적으로 변하는 변수 y라고 하자. 이때 변수 x의 값은 독립적으로 변할 수 있는 것에 반해, y값은 계속해서 x의 값에 의해서, 종속적으로 결정된다. 이때 x를 독립 변수, y를 종속 변수라고도 합니다. 선형 회귀는 한 개 이상의 독립 변수 x와 y의 선형 관계를 모델링한다. 만약, 독립 변수 x가 1개라면 단순 선형 회귀라고 한다. 여기서 x(feature)의 개수가 증가하게되 되면 다중 선형 회귀가 된다.
더욱 쉽게 얘기하면 데이터를 분포 시켜놨을때 해당 데이터와 모양이 제일 비슷한(잘 설명할 수 있는) 선을 긋고싶은 것이다.
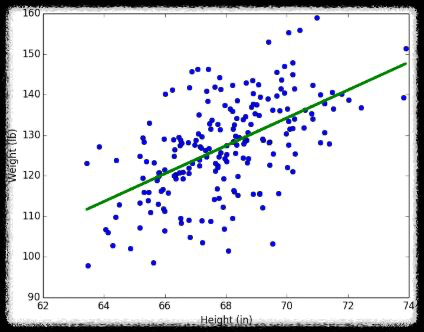
위 사진이 그 선의 예시이다. 해당 선을 더 정교하고 효율적으로 찾기 위해서 아래의 Bias가 나오고 Variance가 나오고 loss function 등등의 개념이 나오는 것이다.
<편향(Bias) & 분산(Variance)>
편향-트레이드 오프는 지도학습에서 에러처리에 중요한 요소이다.

편향(Bias)이 과하게 크면 언더 피팅이 발생한다. 분산이 크면 오버피팅이 발생한다. 언더피팅은 모델이 어떠한 데이터에도 둔감하게 반응해서 결과가 잘 나오지 않고 오버피팅은 과하게 학습 데이터에 최적화되어 있어서 학습데이터와 비슷한 데이터에서만 성능이 좋은 것이다.
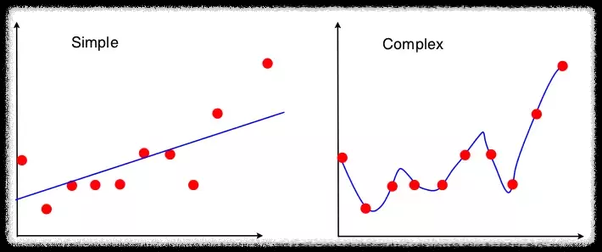
왼쪽은 high bias, low variance 오른쪽은 low bias, high variance이다. 분산은 왼쪽 그래프가 더 작다. 분산은 주어진 데이터로 학습한 모델이 예측한 값의 변동성을 뜻한다. 왼쪽 그래프는 일반화가 잘 되어 있기 때문에 예측 값이 일정한 패턴을 나타낸다. 면, 오른쪽 그래프는 들쑥날쑥한다. 예측 값이 일정한 패턴이 없다는 뜻이다. 즉, 분산이 크다는 뜻이다. 따라서 왼쪽 그래프는 분산이 작고, 오른쪽 그래프는 분산이 크다.
이제 분산과 편향의 trade off에 대해서 알아본다. trade off는 상충관계를 의미한다. 하나의 측면에서 이득을 얻으면 다른 측면에서는 손해를 본다는 뜻이다.
모델의 Error를 구하는 공식은 다음과 같다.
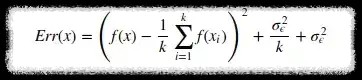
첫 번째 term: 편항(bias)의 제곱
두 번째 term: 분산
세 번째 term: 불가피한 error
위처럼 3가지 모두 합친 Err(x)를 전체 모델의 error라고 한다.
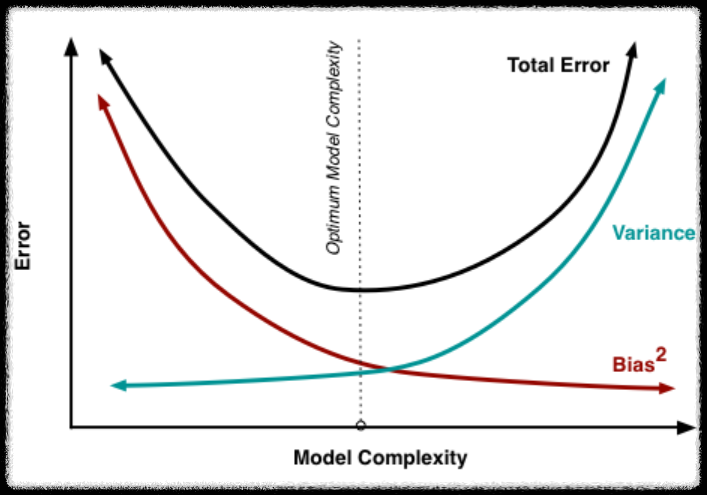
모델이 복삽해질수록 분산은 증가하고 편향은 감소한다. 즉 over fitting이 발생하게 된다. 반대로 모델의 복잡도가 낮을 경우 under fitting이 발생하게 된다. 말 그대로 trade off 관계이기 때문에 오류의 합이 최소가 되는 optimal 한 지점을 찾아야 한다.
출처: https://bkshin.tistory.com/entry/머신러닝-12-편향 Bias와-분산 Variance-Trade-off
머신러닝 - 12. 편향(Bias)과 분산(Variance) Trade-off
편향-분산 트레이드오프 (Bias-Variance Trade-off)는 지도 학습(Supervised learning)에서 error를 처리할 때 중요하게 생각해야 하는 요소입니다. 우선, 아래 그림을 통해 편향(Bias)과 분산(Variance)의 관계를
bkshin.tistory.com
Over Fitting과 Under Fitting에 대해서 조금 더 자세하게 다뤄보고자 한다.
오늘날의 ML Model들은 점점 더 복잡해지는 경향이 있다. 따라서 "Curse of Dimension" 즉 "차원의 저주" 문제를 피하기 어렵다.
쉽게 생각하면 머신러닝에서 훈련 샘플의 특징(feature)이 아주 많으면(수백, 수천 개) 훈련이 느리고 좋은 결과를 얻기 어렵다.
특징(feature)을 변수라고 볼 수 있는데 차원이 증가할수록 변수도 증가한다. 차원이 증가함에 따라 개별 차원 내에서 학습할 데이터의 수가 적어진다. 다만 이러한 일은 항상 발생하는 것은 아니고 관측치보다 변수 수가 많아지는 경우에 이러한 문제가 발생한다.
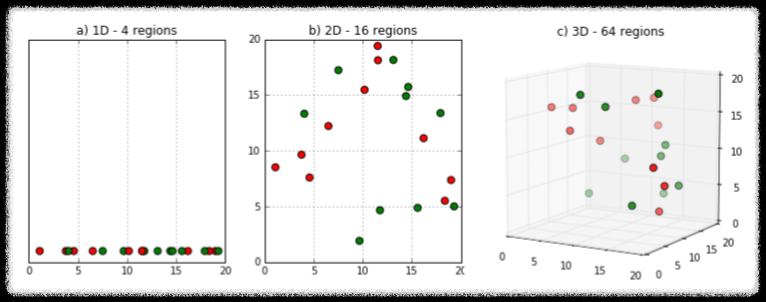
위 그림을 보면 동일한 데이터에 차원이 증가할수록 빈 공간이 많아진다. 이러한 빈 공간은 정보가 없이 0으로 채워진다. 따라서 모델 성능이 저하되는 결과를 불러온다.
고차원 공간에서 훈련 데이터 사이뿐만 아니라 새로운 샘플 데이터와도 멀리 떨어져 있을 확률이 높다. 따라서 외삽법(=보외법)을 이용한다고 하는데 이러하면 오버피팅이 발생할 확률이 높다고 한다. 간단하게 관측된 값을 바탕으로 미래값을 추정한다고 하는데 애초에 base가 된 데이터가 존재하니 오버피팅의 위험성이 있는 건 당연하다. 실제로 많이 쓰고 있는 방법은 아닌 것 같아서 간략하게 소개하고 넘어간다.
차원의 저주를 해결하는 가장 확실한 방법은 데이터의 수를 늘리는 것이다. 그 외에도 Dropout, LASSO, Ensemble 등의 방법이 존재한다. 각각을 다뤄보고자 한다.
<Dropout>
Dropout은 과적합을 막기 위한 정규화 기법의 한 종류다.
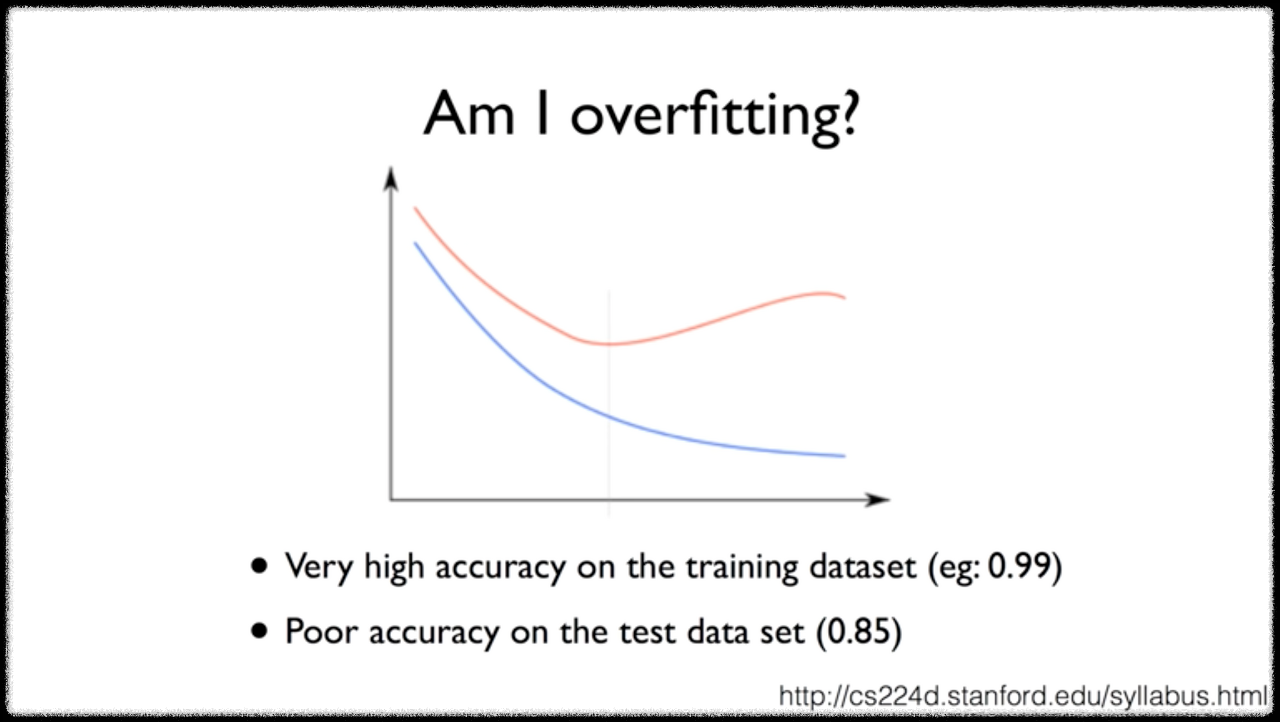
해당 그림을 보면 x축을 layer의 수라고 했을 때 x축이 증가할수록 파란 선(Training에 대한 loss값)은 감소하지만 붉은 선(Test set에 대한 loss값)은 증가한다고 볼 수 있다. 여기서 layer란 앞에서 말한 특징, feature, 변수로 이해해도 좋을 것 같다.

위 사진처럼 해당 객체가 고양이인지 아닌지 분류하는 문제를 푼다고 한다. 고양이는 다양한 특징을 갖고 있을 것이다. 특징은 많게 잡으면 50가지도 넘게 있을 수 있다. 그러나 고양이인지 아닌지 판단할 때 해당 50개의 특징을 전부 사용하는 것은 굉장히 비효율적이다. 적당한 수의 특징만으로 구분을 잘 해내는 모델이 좋은 모델이라고 볼 수 있다.
"사공이 많으면 배가 산으로 간다."가 적합한 것 같다.
신경망에서 들어오는 입력을 무작위로 꺼버리는 것이다. 즉, 선택적으로 노드(뉴런)를 drop 하는 것이다. 따라서 이는 Training Data에는 조금 덜 민감해지겠지만 결론적으로 일반화(Regularization)가 좀 더 잘 이루어지도록 한다. Dropout은 Training때만 사용한다. 당연한 얘기다. Test때 뉴런을 랜덤으로 껐다 켰다 하면 테스트할 때마다 결과가 달라질 것이다.
Dropout의 단점은 비용함수(cost function, loss function, objective function 다 같은 말이다.)가 제대로 하강하는지 확인이 어렵다.
'AI & Data Science > LG Aimers' 카테고리의 다른 글
| 3. 지도학습(회귀,분류) - 4. Least-Squares, Normal Equation (0) | 2023.01.14 |
|---|---|
| 3. 지도학습(회귀,분류) - 3. Optimization(최적화) GD,Adam (0) | 2023.01.14 |
| 3. 지도학습(회귀,분류) - 2. Hypothesis, Cost Function (0) | 2023.01.14 |
| LG Aimers 선정 & 수료 (0) | 2022.12.26 |



