Pandas란?
구조화된 데이터의 처리를 지원하는 파이썬 라이브러리이다. 고성능 배열 계산 라이브러리인 numpy와 통합하여 강력한 스프레드시트 처리 기능을 제공한다. 인덱싱, 연산용 함수, 전처리 함수 등을 제공한다.

series는 DataFrame 중 하나의 column에 해당하는 데이터의 모음 object이다. 즉, Column Vector를 표현하는 object이다.
DataFrame은 Data Table 전체를 포함하는 Object이다.
panda 라이브러리를 pd라는 이름으로 호출한다.
df_data는 csv 형태로 데이터를 읽어 들이고 sepertae는 빈 공간, column은 존재하지 않는다.

Series에서는 인덱스로 값에 접근하는 것이 가능하다.
example_obj ["a"]는 1.0을 값으로 갖는다.
example_obj ["b"] = 3.0 이런 식으로 값을 입력하는 것도 가능하다.


왼쪽 그림은 위에서부터 순서대로 값 리스트만, Index 리스트만, data에 대한 정보를 저장하는 것이고
오른쪽 그림은 index 값을 기준으로 series를 생성하는 것이다.
Data Table 이란 이러한 Series들의 집합이다. 기본이 2차원이다.

주피터 노트북에서 실습을 해보았다.
raw_data라는 변수에 데이터를 만들어 주었다.
각 리스트의 데이터 명을 column 명으로 지정해준다.
출력하면 다음과 같다.

loc는 인덱스를 이름으로 받고
iloc는 인덱스를 index number로 받는다.

특정 조건에 따라서 boolean으로 받는 것도 가능하고 특정 행이나 열을 삭제하는 것도 가능하다.

인덱스와 데이터를 설정해서 series를 만들고 인덱스의 값이 같은 것 끼리 연산되는 것을 볼 수 있다.
연산자를 이용한 연산과 add 함수를 이용한 연산이 동일한 결과를 보임을 알 수 있다.

그러나 DataFrame과 Series 사이의 연산은 조금 다르다.
Series의 각 name이 DataFrame의 column명과 동일하다면 칼럼을 기준으로 broadcasting이 발생한다.
이때 axis=0를 해주면 column별로 연산을 해주게 된다. 만약에 axis=1로 설정하면 row별로 연산이 이루어진다.
<Pandas Built in Funtions>
- describe: 데이터 요약 정보
- unique: series data의 유일한 값을 list로 반환함
- sum: column 혹은 row의 값의 합을 의미 axis로 설정 가능
- isnull: column 혹은 row의 값이 null인지 확인 가능
- sort_values: column값을 기준으로 데이터를 sorting
- correlation & covariance: 상관계수와 공분산을 구하는 함수
<Group By>

SQL의 Groupby와 유사한 기능을 한다. 특정 기준으로 칼럼을 묶어서 연산을 할 수 있다. 한 개 이상의 칼럼을 묶는 것도 가능하다.
엑셀의 피벗테이블과 유사하다. 두 개의 칼럼을 groupby 할 경우 인덱스가 두 개 생긴다.


unstack() 함수를 사용해서 matrix 형태로 전환 가능하다.
swaplevel() 함수를 사용해서 index level 변경이 가능하다.
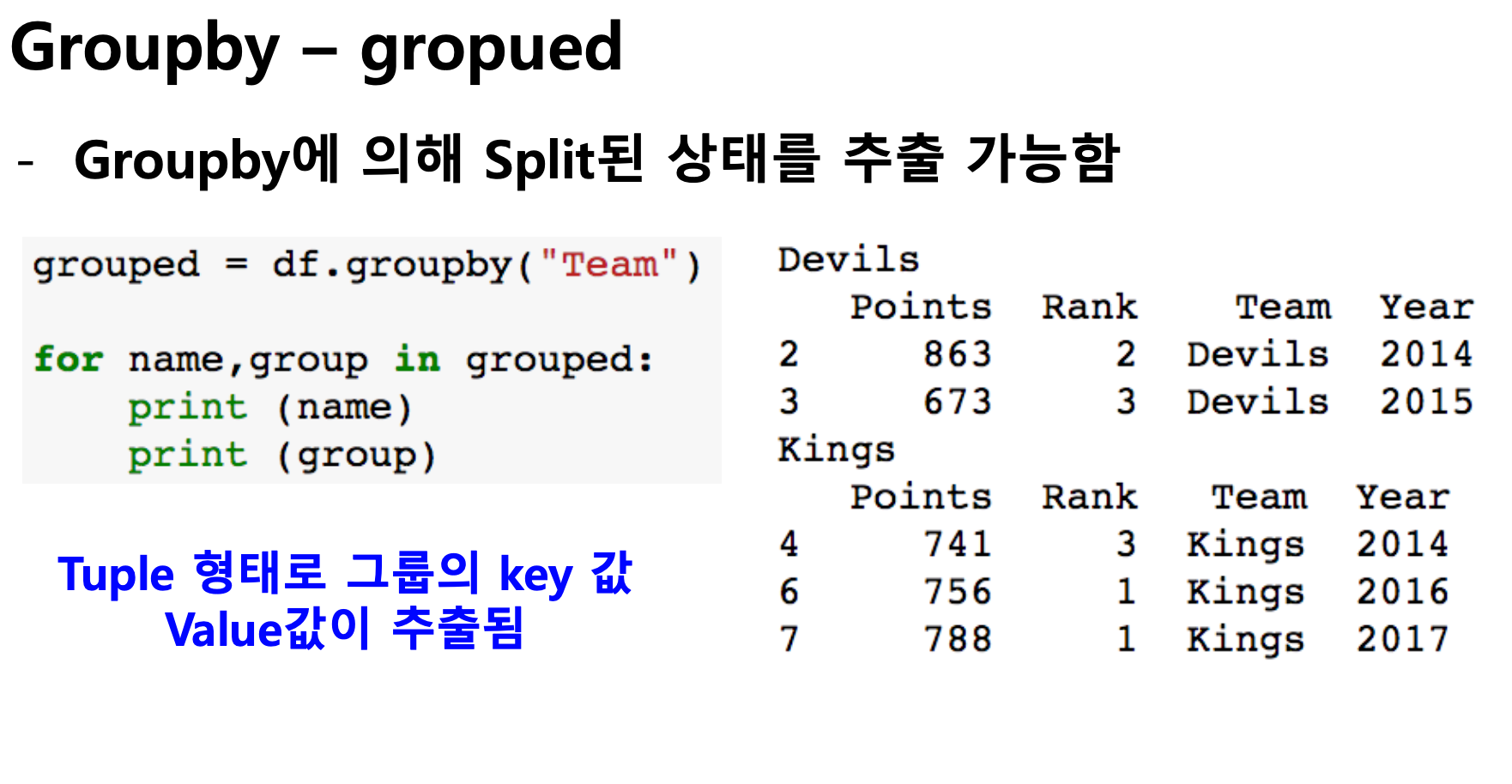


grouped를 활용해서 split 된 상태로 추출 가능하고 기타 함수를 이용해 부가적인 기능을 사용할 수 있다.
DB connection을 이용해 DB를 연결하는 것도 가능하고 pickle과 엑셀 파일도 사용 가능하다.
'AI & Data Science' 카테고리의 다른 글
| BoostCourse AI Pre-Course) 확률론 (0) | 2022.08.02 |
|---|---|
| BoostCourse AI Pre-Course) 딥러닝의 학습방법 이해하기 (0) | 2022.08.02 |
| BoostCourse AI Pre-Course) 기초 수학(경사하강법) (0) | 2022.07.29 |
| BoostCourse AI Pre-Course) 기초 수학(numpy,벡터,행렬) (0) | 2022.07.26 |
| BoostCourse AI Pre-Course) Python Data Handling (0) | 2022.07.25 |



