머신러닝에 대한 자료를 인터넷에서 많이 찾아보았다.
좋은 자료도 많았지만 아직 나의 실력 부족으로 완전히 이해하기는 어려움을 느끼고 진짜 입문서를 찾아서 좀 헤맸다.
오승환 님 께서 쓰신 '파이썬 딥러닝 머신러닝 입문'이라는 책을 접하게 되고 가독성도 좋고 이해도 잘 가는 책이라고 생각해서 공부 중이다.
판다스(Pandas) 라이브러리에선 1차원 배열 형태의 Series와 2차원 배열 형태의 DataFrame의 자료구조를 지원한다.
DataFrame의 각 열은 각자의 Series로 구성된다. 각자의 열은 열 이름을 갖고 행 방향은 행 index로 구분한다.
loc [] 인덱서로 시리즈 객체의 원소를 추출할 수 있다. loc [1:3]은 인덱스 1번부터 3번까지의 원소를 추출한다.
리스트의 슬라이싱 기능과 차이점은 마지막 원소를 포함하는 것이니 기억해 두는 것이 좋겠다.
import pandas as pd #pd라는 이름으로 pandas 라이브러리 호출
data1 = ('a','b','c','d','e') #튜플 자료형
sr1 = pd.Series(data1) #pandas의 Series 자료형으로 변환
data2 = (1,2,3.14,100,-10) #튜플 자료형
sr2 = pd.Series(data2) #pandas의 Series 자료형으로 변환
dict_data = {'c0':sr1, 'c1':sr2} #열의 속성 c0 과 c1에 각 시리즈 할당
df1 = pd.DataFrame(dict_data) #두개의 Series 자료형을 합쳐서 DataFrame으로 만듦
df1.columns = ['string','number'] #df1 의 각 열의 이름을 c0,c1 에서 string, number로 바꿈
df1.index = ['r0','r1','r2','r3','r4'] # 행의 이름도 변경
df1.loc['r2','number'] #loc을 사용해서 특정 위치의 원소 추출 가능
df1.loc[:,'string'] #모든 행이 선택되고 이중 string 열만 추출된다.
머신러닝은 정답이 있는 입력 데이터를 모델에 투입하면 입력과 정답 데이터 사이의 관계를 찾는다.
이를 통해 결과를 예측할 수 있다.
또한 정답이 주어지지 않은 데이터들의 경우 규칙이나 패턴을 알아낼 수 있다.
이처럼 사람이 규칙을 정해주는 것이 아니라 컴퓨터가 스스로 학습해서 문제를 해결하는 것이다.
지도 학습 - 정답이 주어진다, x와 y 사이의 관계식, feature을 통해서 찾아내는 관계식을 통해서 target을 예측
비지도 학습 - x 데이터만 제공 x사이의 존재하는 패턴이나 규칙을 찾는 것이 목표
회귀 - 데이터 분포를 가장 잘 설명할 수 있는 관계식을 찾는 것이 목표 ex) 과거의 데이터를 바탕으로 주가 예측
분류 - 목표 레이블을 가장 잘 구분할 수 있는 경계를 나타내는 함수 식을 찾는 것이 목표.
관계를 찾지만 목표 레이블이 연속적이지 않은 이산적인 값을 의미(이진 분류, 다중 분류)
ex) 여러 장의 강아지와 고양이 사진들 중 고양이와 강아지로 묶어서 분류하기
아래의 사진들은 책에서 도움이 될만한 내용들을 캡처해둔 것이다.
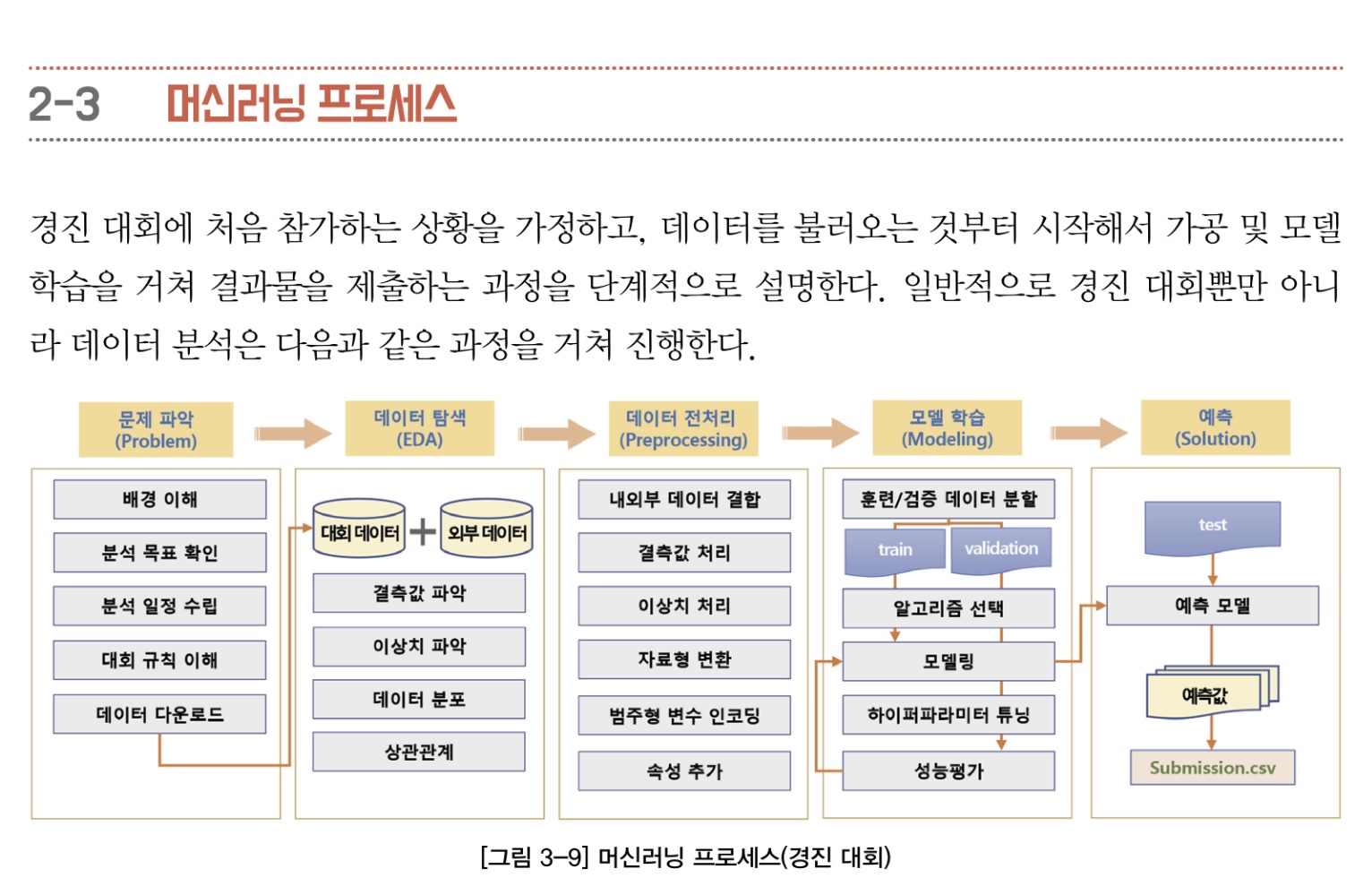
내가 목표로 하는 캐글의 큰 틀이고 요구하는 사항들이다.

'AI & Data Science' 카테고리의 다른 글
| BoostCourse AI Pre-Course) Python Module and Project (0) | 2022.07.24 |
|---|---|
| 인공지능 시험 정리 (0) | 2022.06.11 |
| 파이썬 딥러닝 머신러닝 입문 - 분류 (0) | 2022.01.21 |
| 파이썬 딥러닝 머신러닝 입문 - 일차함수 관계식 찾기 (0) | 2022.01.21 |
| Logistic Regression(로지스틱 회귀) (0) | 2022.01.14 |


