#3가지 종류의 붓꽃에 대한 데이터셋으로 다중분류
import pandas as pd
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
import seaborn as sns
iris = datasets.load_iris() #datasets에 기본적으로 존재하는 iris 데이터를 호출
iris.keys()
#print(iris['DESCR']) #iris 데이터셋에 대한 '설명'이다 설명변수 4개(feature), 목표변수 3종(class)
#print("데이터셋 크기: ",iris['target'].shape) #target 속성의 데이터셋 크기
#print("데이터셋 내용: ",iris['target']) #target 속성의 데이터셋 내용
#print("데이터셋 크기: ",iris['data'].shape) #150행 4열(꽃받침 길이,폭, 꽃잎의 길이,폭)
#print("데이터셋 내용: ",iris['data']) #150개의 꽃 샘플이 있고 이 안에 4개의 데이터 값이 있다.
df = pd.DataFrame(iris['data'],columns=iris['feature_names']) #pandas로 변환
df.columns = ['sepal_length','sepal_width','petal_length','petal_width']
df['Target'] = iris['target'] #iris의의 타겟을 df의 Target(가장 오른쪽열)에 추가
#df.describe() #샘플의 평균,표준편차,최솟값,최댓값 등
#df.isnull().sum() #결측값이 있을땐 True, 없을땐 False 반환
#df.duplicated().sum() #동일한 샘플이 중복되어있는지 있을땐 True, 없을땐 False
#df.loc[df.duplicated(),:] #중복샘플 추출
#df.loc[(df.sepal_length == 5.8)&(df.petal_width == 1.9),:] #어디랑 겹치는지 확인
#df = df.drop_duplicates() #중복으로 겹치는는 101과 142번 샘플중 142번 삭제
#df.corr() #변수간의 상관관계 분석
###################데이터 시각화##################
sns.set(font_scale=1.2) #seaborn의 폰트 사이즈 1.2
#sns.heatmap(data=df.corr(), square = True, annot = True, cbar=True) #히트맵으로 표현
#plt.show()
df['Target'].value_counts() #Target 값의 분포 0,1,2 50개씩씩
#plt.hist(x='sepal_length', data=df) #'sepal length'의 값의 분포
#plt.show()
#sns.displot(x='sepal_width', kind='hist', data=df) #kind로 hist 옵션을 선택해서 히스토그램 출력
#sns.displot(x='petal_width', kind='kde', data=df) #kind로 kde 옵션을을 선택해서 커널밀도 출력
#sns.displot(x='sepal_length', hue='Target', kind='kde', data=df)
#hue로 목표변수를 지정해 hue의 Target열의의 품종별로 구분하도록 설정
#for col in ['sepal_length','sepal_width','petal_length','petal_width']:
#sns.displot(x=col, hue='Target', kind ='kde', data=df) #반복문으로 한번에 출력
#sns.pairplot(df, hue = 'Target', size = 2.5, diag_kind='kde') #feature간의 관계를를 한번에에 그림
#plt.show()
############Train-Test 데이터셋 분할할###########
from sklearn.model_selection import train_test_split
x_data = df.loc[:,'sepal_length':'petal_width']
y_data = df.loc[:,'Target']
x_train, x_test, y_train, y_test = train_test_split(x_data, y_data,
test_size = 0.2,
shuffle = True,
random_state=20)
# 80%는 훈련데이터 20%는 테스트데이터로 분류
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)지도 학습 유형 중에서 분류 문제이다.
여기서는 sklearn 패키지에 내장되어 있는 붓꽃 데이터셋을 이용한다.
1. 붓꽃 데이터셋을 로딩 하고 iris.keys()를 통해서 딕셔너리 자료형인 데이터셋의 키값을 확인한다.
2. 데이터셋은 3종류의 붓꽃이 있고 각 종마다 50개의 샘플이 있다. 그리고 설명 변수의 feature는 speal 과 petal의 각 length와 width로 되어 있다. iris['DESCR'] 로 확인 가능하다. 참고로 DESCR은 '설명' 이라는 뜻이다.
3. 목표변수는 iris['target'] 이다. 이는 150개의 샘플 데이터 이다.
4. iris['data']는 150개의 행과 설명변수와 같은 4개의 열로 이루어져 있다.
5. df라는 변수명에 DataFrame 형태로 바꾼다. 행 부분에는 data를 열 부분에는 feature_names를 지정해준다.
6. 이름도 바꿔줘서 feature_names에 있는 in cm를 없애고 df['Target'] 에 iris['target']열을 추가해준다.
7. df.info() 로 기본정보 확인이 가능하고 df.descirbe()를 통해서 샘플의 평균,표준편차, 최댓값 등 통계 정보를 요약해준다.
8. df.isnull()을 통해서 각 원소가 missing value인지 체크, 정상이면 0(False)를 반환, 결측값이 존재하면 1(True)를 반환 따라서 sum()을 통해서 결측값의 갯수를 알 수 있다. -> 결측값이 존재한다면 별도의 전처리가 필요하다.
9. df.duplicated() 를 통해서 중복 샘플이 존재하는지 확인 가능하다. 존재한다면 1, 그렇지 않다면 0 을 반환한다. 따라서 sum()을 이용해서 값을 확인하면 중복된 샘플의 갯수를 확인 가능하다.
10. df.loc[df.duplicated(),:] 를 통해서 중복되는 행과 그 행에 존재하는 열을 전부 출력한다.
11. 출력된 feature 데이터를 보고 조건에 맞게 추출한다.
12. df = df.drop_duplicates()를 이용하면 뒤에 나온 중복된 샘플이 제거 된다.
13. df.corr()을 통해서 변수간의 상관 관계를 분석한다.
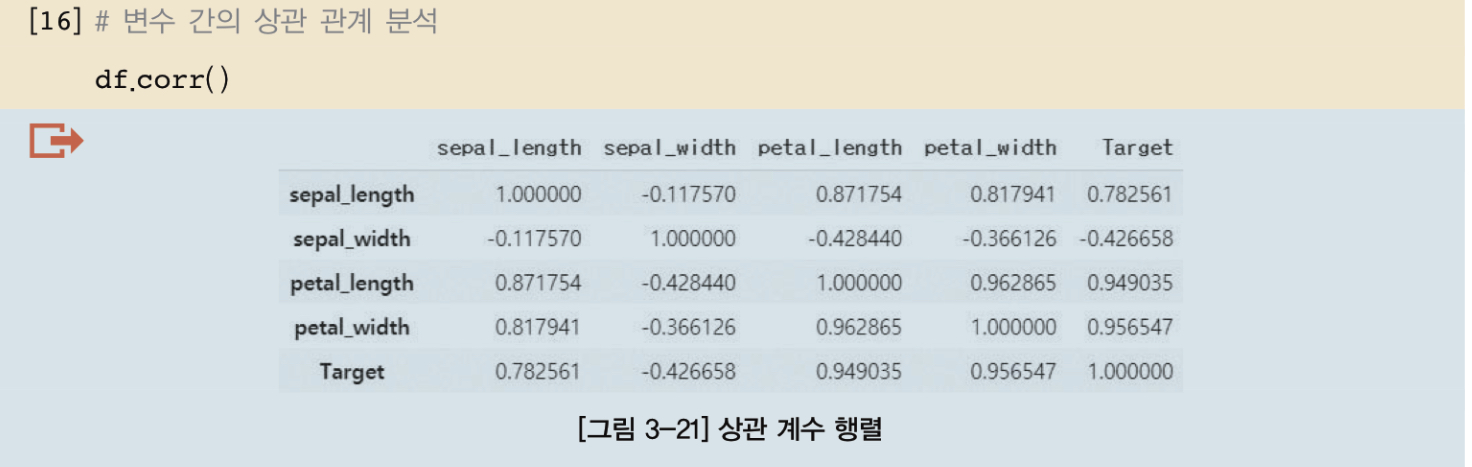
14. 목표레이블은 상관 계수가 -0.42인 sepal_width를 제외한 나머지 피처들과 상관 관계가 높다.
=============================데이터 시각화=============================
15. 시각화 패키지는 matplotlib 과 seaborn이 필요하다.
16. heatmap이란 숫자 대신 색상의 그라데이션으로 표현된 엑셀의 워크시트라고 생각하면 좋을것 같다. 꼭 열화상카메라로 찍은 사진과 비슷하게 생긴 테이블이 나온다. 괜히 'heat'map이 아니다.
data에 위에 만들었던 변수관의 상관관계인 df.corr()을 넣는다. annot은 상관계수 숫자를 표현할 것인지, cbar은 colorbar을 생성할 것인지, square은 cell을 정사각형으로 출력하는 것을 의미힌다.
17. displot() 함수를 통해서 각 feature의 데이터 표본을 hist,kde 등으로 표현 가능하다. 여기서 hue = 'Target'을 할당해서 열에 존재하는 품종별로 데이터를 분하여 그래프로 그릴 수 있다.
18. pairplot()을 이용하면 서로 다른 피쳐간에 관계를 나타내는 그래프를 만들 수 있다.
19. 이를 통해 알게된 점은 다음과 같다. 클래스0(setosa 품종)은 sepal_length가 짧은 편이므로 모델학습에 고려해야 하는 유의미한 feature 이다. petal_length와 petal_width도 품종별로 분포의 중심 위치가 다르고, 데이터의 분산도에도 차이가 있다. sepal_width는 품종별로 다른 feature에 비해 유의미한 큰 차이를 보이지 않는 것을 알 수 있다.

=============================Train-Test 데이터셋 분할=============================
20. 모델 학습에 사용할 훈련(Train) 데이터 와 모델 성능을 평가하는데 사용할 테스트(Test) 데이터를 분할한다.
21. sklearn 의 train_test_split 함수를 사용하면 편하게 나눌 수 있다.
22. x_data에 4열의 feature 데이터를 입력한다. 행은 모든 행이 포함 되어야 한다. y_data는 목표 레이블이 되어야 하므로 Target을 지정한다.
23. test_size는 실수 형태로(여기서는 0.2 == 20%) 저장해서 테스트 데이터로 분류된다. 당연히 대부분의 경우에 훈련 데이터가 테스트 데이터 보다 많아야 한다. random_state를 지정하면 반복하더라도 동일한 값을 얻을 수 있다.
'AI & Data Science' 카테고리의 다른 글
| BoostCourse AI Pre-Course) Python Module and Project (0) | 2022.07.24 |
|---|---|
| 인공지능 시험 정리 (0) | 2022.06.11 |
| 파이썬 딥러닝 머신러닝 입문 - pandas (0) | 2022.01.21 |
| 파이썬 딥러닝 머신러닝 입문 - 일차함수 관계식 찾기 (0) | 2022.01.21 |
| Logistic Regression(로지스틱 회귀) (0) | 2022.01.14 |

