뉴럴 네트워크는 인간의 시냅스를 본떠서 만든 인공 신경망이다.
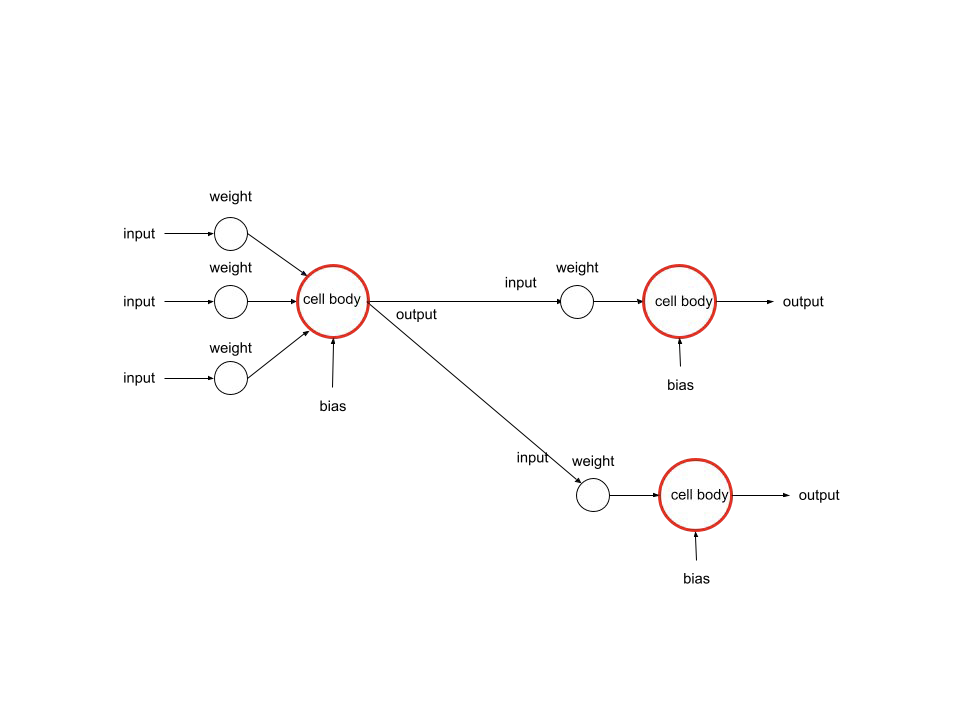
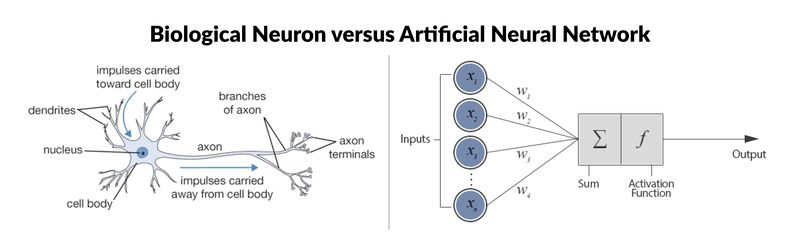
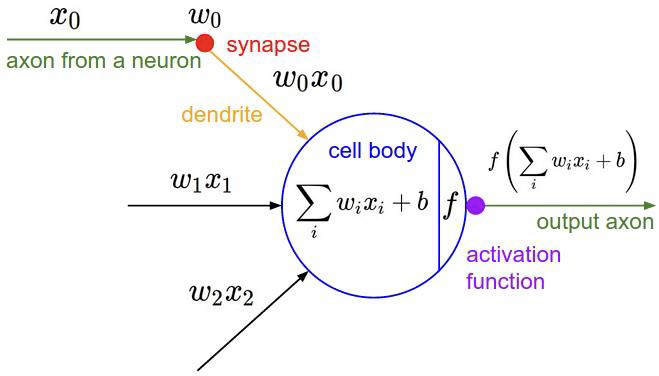
가중치: 입력값에 따른 중요도를 의미한다. 손실함수가 최소가 되는 방향으로 값을 수정해 간다.
가중합: sum(입력값 * 가중치) 를 의미한다.
편향(bias): 가중합에 더해주는 상수이다. 초기에는 랜덤값으로 주어진다. 학습을 하면서 역전파를 통해서 bias 값을 수정해 간다.
이는 loss function이 최소가 되는 방향으로 진행된다. 활성화 함수를 좌우로 움직여서 다양한 학습을 가능하도록 한다.
활성화 함수: 활성화 함수는 비선형성을 추가하여 복잡한 문제를 다룰 수 있도록 한다. 뉴럴 네트워크의 출력값을 제한해서 모델의 안정성을 높인다.
역전파 알고리즘: 편미분을 사용한다. loss function의 기울기를 계산하고 각 가중치와 편향에 대한 기울기를 계산한다. 이를 바탕으로 가중치와 편향을 조정하고 loss function 값이 최소가 되도록 한다.
1. 입력층에서부터 순전파(Forward Propagation) 과정을 거쳐 출력층의 출력값을 계산합니다.
2. 손실 함수를 이용해 출력값과 실제값의 차이를 계산합니다.
3. 출력층에서부터 역방향으로 오차를 전파시킵니다. 이 때, 오차는 손실 함수의 기울기(gradient)와 활성화 함수의 기울기(activation function gradient)를 곱하여 구합니다.
4. 이전 층으로 이동하면서, 가중치와 편향을 조정합니다. 가중치와 편향을 조정하는 방법은 경사하강법(Gradient Descent)과 유사합니다. 즉, 가중치와 편향을 현재 값에서 학습률(learning rate)과 기울기의 곱만큼 조정합니다.
5. 위 과정을 반복하여, 손실 함수를 최소화하는 최적의 가중치와 편향을 찾습니다.
Tensorflow: 오픈소스, 무료, 구글 브레인팀, 2015, 딥러닝 프레임워크
keras: 오픈소스, 무료, 2.0부터 텐서플로우에 흡수됨, 쉬움
ML Modeling 과정:
데이터 준비(데이터 수집 및 전처리) -> 모델 디자인(파라미터, 모델 선정) -> 모델 학습 -> 모델 평가
정규화: 데이터 스케일 조절해서 모델의 성능을 높이고 오버피팅 방지.
reshape(): 데이터의 차원을 바꿔준다.
원핫 인코딩: 범주형(categorical) 데이터를 numerical 데이터로 바꿔줌,
model.summary(): output shape와 layer, param 숫자를 제공한다.
param: Keras 모델의 학습 가능한 파라미터의 개수를 의미, 가중치 개수 + 편향 개수.
편향 개수 = 출력 뉴런의 개수
가중치 개수 = 출력 뉴런 * 입력 뉴런의 개수
model = Sequential()
model.add(Dense(units=64, activation='relu', input_shape=(784,)))
model.add(Dense(units=10, activation='softmax'))
'''
첫번째 레이어 가중치 개수: 784 * 64
첫번째 레이어 편향 개수: 64
두번째 레이어 가중치 개수: 64 * 10
두번째 레이어 편향 개수: 10
'''손실함수: 모델의 예측값과 실제값 사이를 나타내는 함수. 낮추는 것을 목표로 학습해야 한다.(categorical_Crossentropy, mean_squared_error, binary_crossentropy)
옵티마이저: 가중치와 절편 등의 파라미터를 조정하는 방법을 제공하는 알고리즘입니다. 즉, 손실 함수를 최소화하는 파라미터를 찾아내는 역할.(RMSprop, SGD, Adam)
metric:모델이 컴파일될 때 평가 지표를 지정하는 데 사용됩니다. 이러한 평가 지표는 모델이 학습하는 동안 모니터링되며, 모델이 얼마나 잘 수행되는지 평가하는 데 사용
epoch: 학습 횟수, 과도한 epoch는 오버피팅이 발생한다.
Batch Size: 한 번에 모델에 입력될 데이터의 크기, 너무 작으면 노이즈가 많이 생긴다(업데이트가 자주 발생하니깐), 너무 크면 메모리에 부담이 된다.
만약 데이터가 60000개, 배치 사이즈가 10이라고 가정. 1 epoch당 60000/10 = 6000번의 가중치와 편향이 업데이트된다.
오버피팅: 모델이 학습 데이터셋에 과하게 적합된 형태.
Convolution Layer: 특징 추출을 하는 필터, 내적 사용, (원본크기-필터크기+1)
Pooling Layer: 이미지 축소, 연관이 덜한 부분 삭제, max pooling(가장 큰 값), average pooling(평균)
flatten: 이미지 정보를 1차원 데이터로 바꿔서 fully connected layer가 인식할 수 있도록 한다.
fully connected layer: flatten 된 입력 데이터로 분류 수행.(Output = Activation(Weight * Input + Bias))
CNN에서 가중치 개수 입력 차원:
첫 번째 컨볼루션 레이어: (현재 출력 차원 수*컨볼루션 크기 *입력 데이터 depth) + 현재 출력 차원 수(bias)
나머지: (이전 출력 차원 수 * 컨볼루션 크기 * 현재 출력 차원 수) + 현재 출력 차원 수(bias)
TensorflowLite:
TensorFlow Lite (for microcontroller)는 마이크로컨트롤러(Microcontroller)에서 머신 러닝 모델을 배포하기 위한 단일 프레임워크를 제공합니다. 이를 위해서는 Tensorflow를 사용하여 데이터를 준비하고 모델을 훈련하고 검증해야 합니다. 그리고 훈련된 모델을 Tensorflow Converter를 사용하여 Tensorflow Lite로 변환한 후, 변환된 모델을 엣지(Edge) 디바이스인 마이크로컨트롤러에 배치하여 모델을 실행합니다. 마이크로컨트롤러에서는 Tensorflow Lite 인터프리터가 모델의 추론(inference)을 실행합니다.
즉, Tensorflow Lite (for microcontroller)를 사용하면 마이크로컨트롤러에서도 머신 러닝 모델을 실행할 수 있으며, 이를 통해 엣지 컴퓨팅(Edge Computing)을 구현할 수 있습니다. 모바일 기기나 IoT 디바이스와 같은 자원이 제한된 환경에서도 효율적인 머신 러닝을 수행할 수 있습니다. 이를 위해서는 데이터 전처리, 모델 훈련, 변환, 배치, 추론 등 여러 과정이 필요하며, Tensorflow Lite (for microcontroller)는 이러한 과정들을 간편하게 수행할 수 있도록 지원합니다.
Arduino: ESP32, Nano33 BLE Sense, Arduino IDE(Serial Plotter)
'AI & Data Science' 카테고리의 다른 글
| 데이터 분석 과제 정리 (0) | 2023.10.19 |
|---|---|
| 2023 스마트 빌딩 빅데이터 분석 경진대회 후기 (최우수상 수상) (0) | 2023.06.24 |
| CNN (0) | 2023.04.01 |
| Isolation Forest (0) | 2023.01.29 |
| 2022 제4회 매치업 스마트시티 아이디어톤(AI 서비스 부문) 후기 (장려상 수상) (0) | 2022.12.26 |


