프로세스(task와 동일한 의미)는 실행 중인 프로그램을 의미한다.
여기서 실행중이라는 것은 메인 메모리에 올라가 있다는 뜻이다.
CPU는 메모리로부터 Program Counter에 대응하는 연산을 fetch 하며, 해당 연산들은 특정 메모리 주소에 대한 추가적인 load, store가 필요할 수 있다.
<Instruction Execute Cycle>
연산 - 실행 순환 과정은 다음과 같다.
1. Instruction Fetch: 연산이 메모리로부터 fetch 된다.
2. Instruction Decode + Operand Fetch: 해당 연산은 decode 되고, 다른 피연산자를 메모리로 부터 fetch 할 수 있다.
3. Instruction Execution: CPU가 Instruction Decode를 실행하고 결과를 다시 메모리에 Store(저장) 한다.
이때 우리는 실행되는 프로세스에 의해 생성된 메모리 주소에만 관심을 갖는다.
<Basic HW>
CPU는 메인 메모리와 프로세서에 자체 내장된 레지스터에만 직접 접근이 가능하다.
메모리 주소를 인자로 하는 기계적 연산이 존재하지만, 디스크(HDD,SSD)를 주소로 인자로 하는 연산은 없다.
따라서 실행되는 모든 연산들과 연산에 사용되는 데이터들은 직접 접근 가능한 메모리 영역에 존재해야 한다.
즉 디스크에 존재하는 데이터 및 코드를 메모리에 미리 옮겨놔야 하는 것이다.
Cache)
CPU에 내장된 레지스터들은 메모리에 있는 정보들 조차 더 빠르게 불러오기 위해 사용한다.
만약에 메모리의 속도도 CPU속도에 비하면 한참 느리다. 만약에 연산중에 필요한 데이터가 메모리에서 아직 넘어오지 않은 경우 CPU는 일시정지를 해야 하고 이것이 누적되면 버퍼링이 생겨 결과적으로 성능상 큰 손해를 본다. 따라서 CPU와 메모리 사이에 속도가 빠른 메모리를 하나 추가시켜 이를 방지하는 것이다.
Base and Limit)
물리적 메모리에 접근하는 속도 뿐만 아니라, 사용자 프로세스가 운영체제에 접근하는 것과 사용자 프로세스를 상호 간에 보호하는 것 역시 고려되어야 한다.
우선 각 프로세스를 분리된 메모리 공간을 사용하도록 한다. 프로세스가 접근 할 수 있는 유효한 메모리 주소의 범위를 정하고 프로세스는 이러한 유효한(legal) 메모리 주소만 접근하도록 할 수 있다.
Base 레지스터는 legal 메모리 주소의 시작값(가장 작은 주소 값)을 정하고, Limit 레지스터는 legal 메모리 주소의 범위를 저장한다.
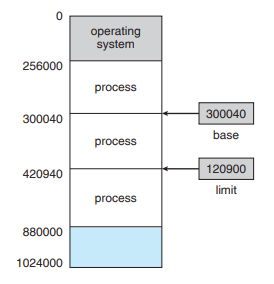
그림에서 base = 300040, limit = 120900이므로 legal 메모리 주소 범위는 300040 ~ 420940 (base + limit)이다
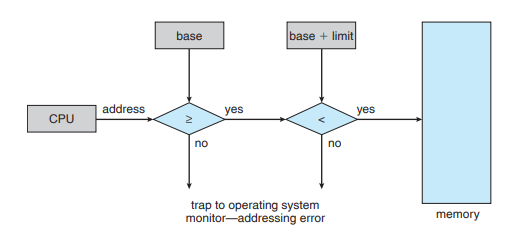
UserMode에서 실행 중인 프로그램의 운영체제 메모리나 다른 사용자의 메모리에 대한 접근 시도는 운영체제에 trap을 발생시켜 Fatal Error(치명적 오류)로 간주된다. 이러한 방법은 사용자 프로그램이 실수 또는 고의에 의해 허가되지 않은 메모리 영역의 코드나 데이터 구조를 수정할 수 없도록 한다.
Base, Limit 레지스터들은 운영체제의 전용 연산에 의해서만 load 된다. 즉 커널 모드에서만 작동하고 이는 운영체제만이 이 레지스터들의 값을 변경할 수 있다는 것을 의미한다.
<Address Binding>
일반적으로 프로그램은 실행 가능한 이진 파일 형태로 디스크에 저장되어 있다가 프로그램이 실행될 때 프로세스 내의 메모리로 이동되어야 한다. 이때 실행을 위해 메모리로 옮겨지는 것을 기다리는 프로세스들은 Input Queue에서 대기한다.
Input Queue에서 프로세스 하나를 선택 해당 프로세스를 메모리에 load 한다. -> 프로세스가 실행되면 메모리의 연산과 데이터들에 접근하게 된다. -> 이후 프로세스가 종료되면, 그 프로세스가 사용하던 메모리 영역은 다시 사용 가능한 메모리 영역이 된다.
대부분의 시스템들은 사용자 프로세스가 물리적 메모리의 어떤 부분을 차지해도 상관없도록 허용한다.
프로그램의 주소는 일반적으로 symbolic 주소 형태인데 컴파일러는 이러한 symbolic 주소를 "이 모듈의 시작 주소로부터 n바이트"라는 실제 주소로 bind 한다.
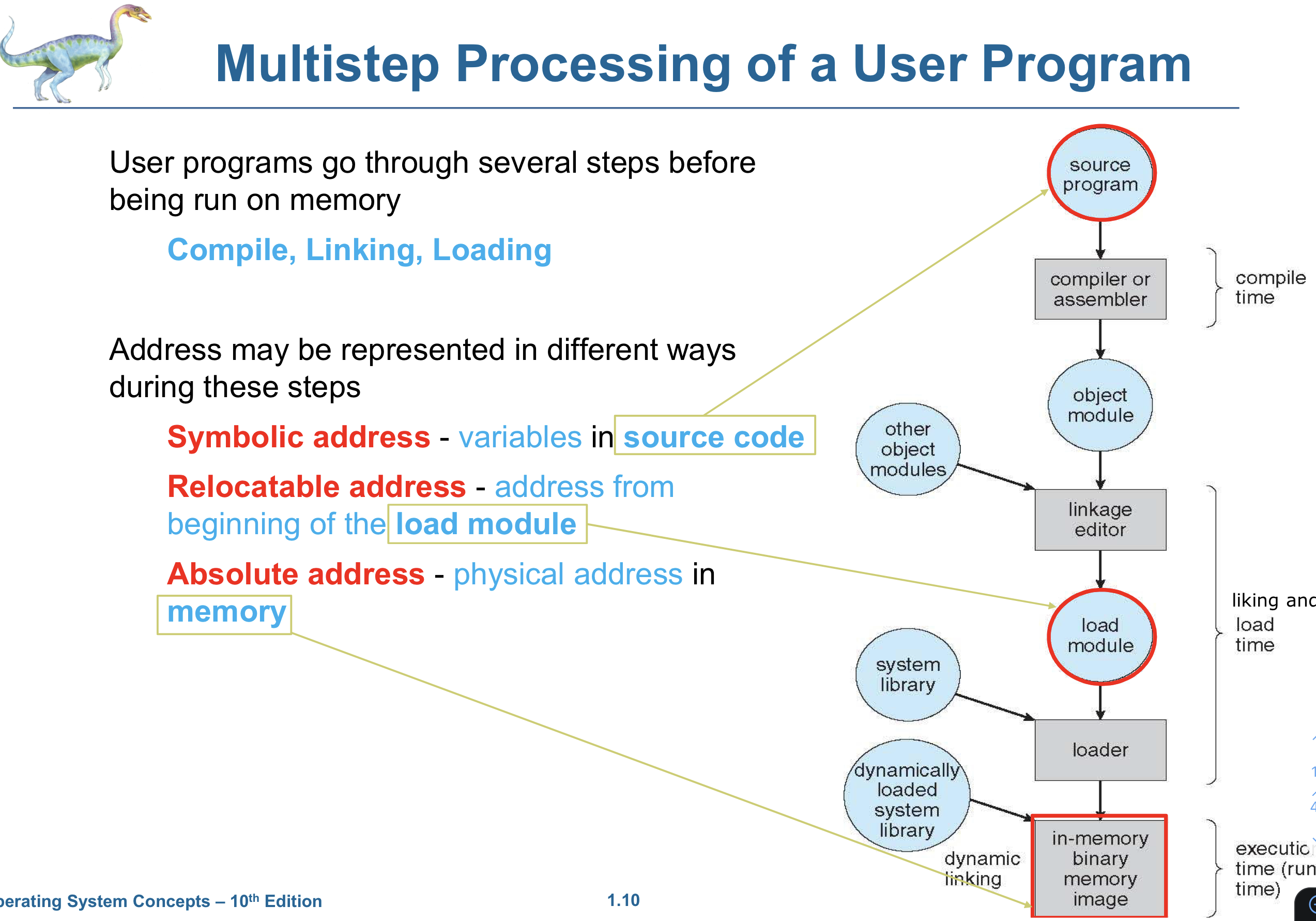
Compile Time)
프로세스가 메모리에서 차지할 영역을 컴파일 시간에 알고 있다면 Absolute Code가 생성될 수 있다.
만약 시작 주소가 변경된다면 재컴파일해야 한다.
Load Time)
컴파일 시간 동안 프로 스세가 차지할 메모리를 알 수 없다면 컴파일러는 반드시 Relocatable Code를 생성한다. 이런 경우 적재 시간 동안 Binding은 연기되고 시작 주소가 변경될 경우 사용자 코드만 다시 Reload 하면 된다.
Execute Time)
메모리의 실제 주소 즉 물리적인 메모리 주소가 정해지게 되고 실행시간 동안 binding은 연기된다.
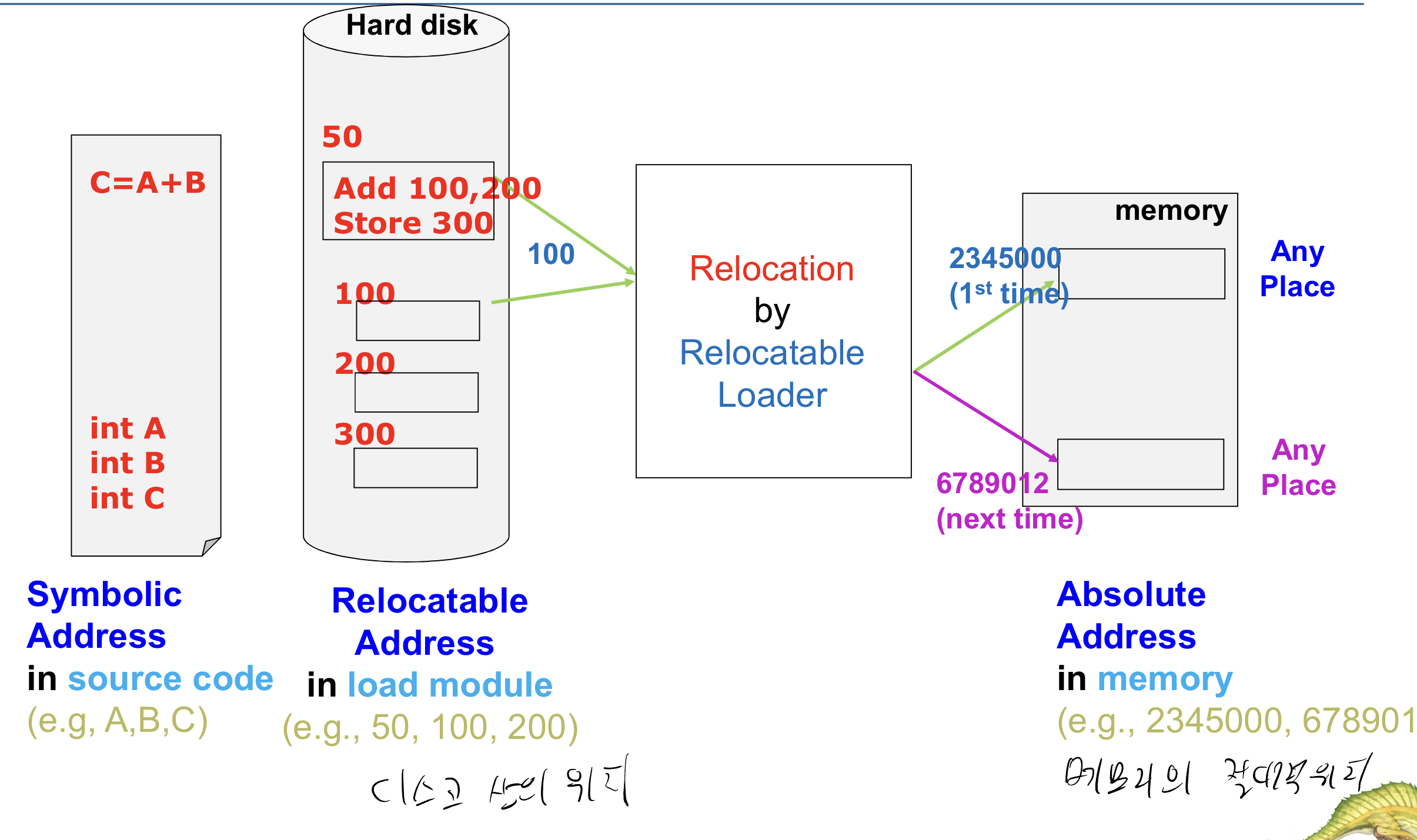
위의 예시를 보면 소스코드 상에서는 symbolic address로 존재한다 이는 하드디스크 상에서 Relocatable Address로 존재하고 이를 Relocation을 통해서 메모리의 물리적 위치의 주소 즉, Absolute Address가 된다.
논리적 주소: CPU에 의해 생성되는 주소 Virtual Memory라고 부르기도 한다.
물리적 주소: 메모리 주소 레지스터에 표시되는 주소
Compile Time과 Load Time에선, Address Binding은 동일한 논리적, 물리적 주소를 생성하지만,
Execute Time의 Address Binding은 서로 다른 논리적, 물리적 주소를 생성한다.
<Memory Management Unit>
실행시간 동안 가상 주소를 물리적 주소로 변환해주는 하드웨어이다.
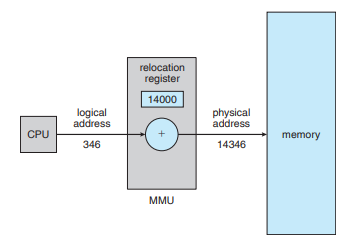
이때 Base Register는 Relocatuin Register가 된다.
사용자 프로세스에 의해 생성되는 모든 주소들에 Relocation 레지스터의 값을 더해 실제 메모리 주소를 구한다.
논리적 주소는 사용되기 전에 반드시 물리적 주소로 바뀌어야 한다.
<메모리 절약>
Dymaic Loading(동적 적재)
프로세스 실행을 위해 모든 프로세스가 physical 메모리에 적재되어야 한다면 프로세스의 크기가 physical 메모리 크기로 제한된다.
1. 모든 루틴은 호출되기 전까지 load 되지 않는다. 즉, 아주 기본적인 데이터만 load 된다.
2. 사용되지 않은 루틴은 절대 호출되지 않으므로 메모리 활용도가 올라간다.
3. 에러 루틴과 같은 희귀한 상황이 발생하여 이를 통제할 때 많은 양의 코드가 필요한 경우 유용하다.
Dynamic Linking(동적 호출)
- DLL (dynamically linked library): 프로그램 실행 중간에 사용자 프로그램에 링킹되어 사용할 수 있는 시스템 라이브러리. 실행 시 한꺼번에 링킹 되지 않고 라이브러리만 로딩된 상태에서 필요할 때 링킹 됨.
- 정적 링킹 (static linking): 시스템 라이브러리가 다른 오브젝트 모듈처럼 한꺼번에 로더에 의해 이진 프로그램 코드로 합쳐짐.
- 동적 링킹 (dynamic linking): 동적 로딩과 비슷하게 링킹 작업을 실행 시간 (execution time)에 수행하는 것.
이 때문에 DLL을 공유 라이브러리 (shared library)로 부르기도 함.
<Contiguous Memory Allocation(연속 메모리 할당)>
여러 사용자 프레스가 동시에 메모리를 사용하는 경우가 있기에 어떻게 메모리를 할당할지 결정해야 한다.
연속 메모리 할당 방식은 프로세스를 단일 구역에 할당하는 방식으로 한 구역에 연속적으로 할당되는 특징을 가진다.
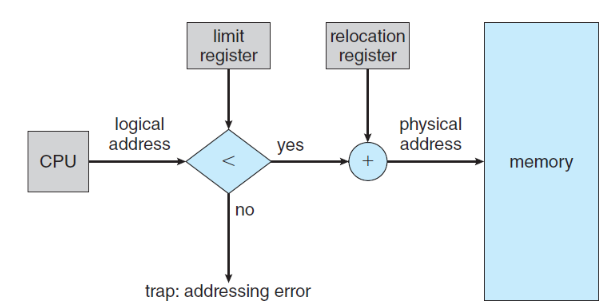
이때 메모리는 relocation Register와 limit Register에 의해 이루어짐.
MMU는 logical address를 pyhisical address로 동적으로 할당한다.
하나 이러한 방식으로 할당 시 문제가 생기는데 프로세스의 크기가 제각각이기 때문에 구멍(hole)이 생긴다.
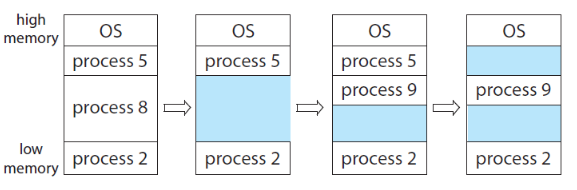
하늘색으로 칠해진 부분을 hole이라고 하고 이는 free partition이다. hole의 총합의 크기가 커지면 메모리의 낭비가 심해진다.
3가지 해결 방법이 있다.
- 최초 적합 (first-fit): 구멍들을 탐색하다가 할당할 수 있는 가장 첫 번째 구멍에 할당하는 것. (크기만 맞으면 일단 할당한다. 속도는 빠르다)
- 최적 적합 (best-fit): 할당할 수 있는 가장 작은 구멍에 할당하는 것. (이를 위해 구멍들의 리스트를 우선순위 큐로 구현)
- 최악 적합 (worst-fit): 할당할 수 있는 가장 큰 구멍에 할당하는 것
메모리 낭비의 관점에서는 최초 적합과 최적 적합이 최악 접합에 비해 더 낫다.
<Fragmentation>
- 외부 단편화 (external fragmentation): 메모리 공간이 조각조각 나눠져 있어 메모리 할당 요청을 받을 수 없는 상태 (100MB 할당 가능한데 2MB짜리로 다 나눠져 있어 3MB짜리를 할당할 수 없음)
- 내부 단편화 (internal fragmentation): 빈 공간에 메모리를 할당하고 난 뒤 공간이 남아 다른 메모리를 할당할 수 없는 상태
연속 메모리 할당을 하면 외부 단편화 문제가 발생함.
페이징을 하면 내부 단편화 문제가 발생함
<Paging>
프로세스의 물리적 주소 공간을 불연속적으로 쪼개서 관리하는 것. 따라서 외부 단편화 문제를 해결할 수 있다.
OS와 하드웨어의 도움을 받는다.
페이징의 기본 방법은 메모리를 동일한 크기로 쪼개고 이러한 고정 크기의 블록 하나를 프레임이라고 한다.
논리 메모리를 같은 크기로 나는 것을 페이지라고 한다.
따라서 해당 조각을 물리 메모리의 위치에 맞게 올리면 된다. 논리 주소 공간과 물리 주소 공간이 분리되기 때문에 물리 주소를 고려하지 않고 프로그래밍 가능하다.
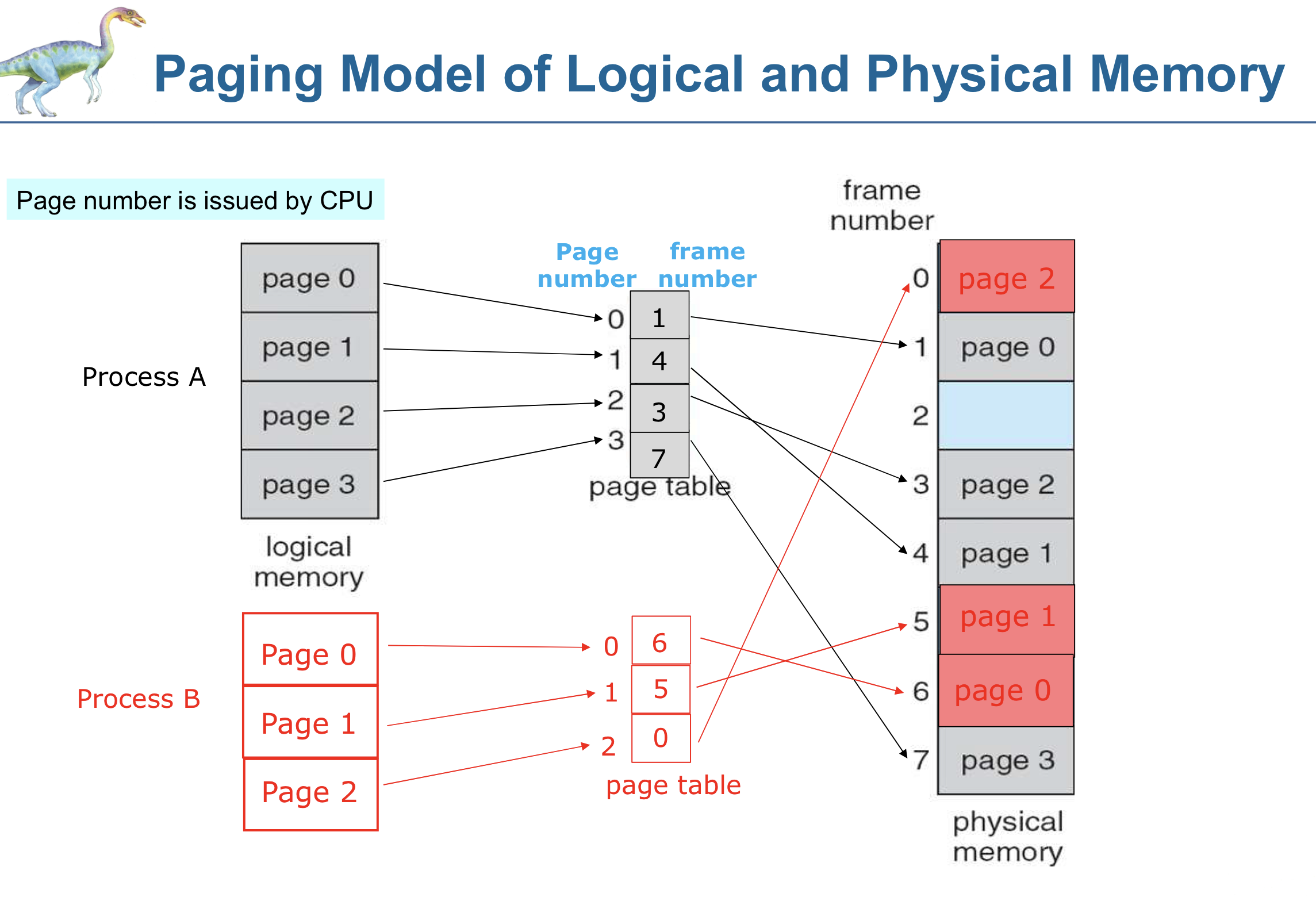
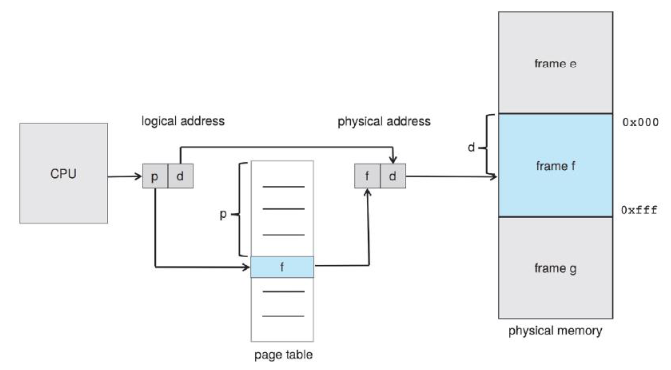
위 그림처럼 일정한 크기의 프레임들이 page table을 통해서 물리적 메모리에 알맞은 위치에 할당된다.
이렇게 넘겨줄 때 page number(p)와 offset(d)만 넘겨주면 된다.
p페이지에 있는 d번째 메모리에 할당하라는 의미이다.
다만 프로세스마다 페이지의 개수가 다르기 때문에 page table을 통해서 관리해야 한다.
페이지의 적절한 크기를 정하는 것도 매우 중요하다. 이는 하드웨어에 의해서 정의된다.
일반적으로 4kb ~ 1GB 사이의 2의 배수로 지정된다.
논리 주소 공간의 크기가 2^m이고 페이지의 크기가 2^n인 경우 페이지의 개수는 m-n, offset의 크기는 n이다.
다만 프로그램의 크기가 커지면 Page Table은 하드웨어만으로 관리가 어려워졌다. 따라서 Page Table Base Register를 따로 만들어서 페이지 테이블의 시작 주소를 가리키도록 한다. Page Table은 Main Memeory에 존재한다.
문맥 교환의 시간은 줄어들지만, 메모리 접근 시간은 오래 걸린다.
TLB)
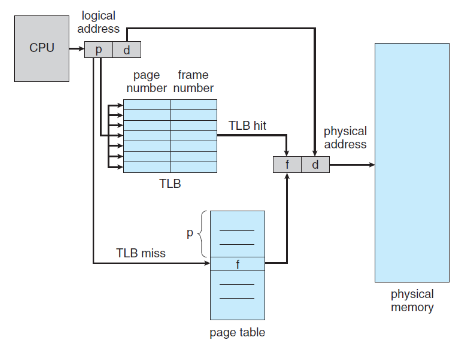
CPU에서 페이지 테이블에 바로 접근하는 것보다 캐시 메모리인 TLB를 거쳐서 접근하는 것이 더 빠른다.
결국 페이지 테이블은 메인 메모리 안에 존재하기 때문에 캐시 메모리보다 속도가 느리기 때문에 버퍼링 발생 가능성이 있다.
TLB hit: 찾고자 하는 페이지 번호가 TLB에 존재하는 경우
TLB miss: 페이지 번호가 TLB에 없는 경우
TLB hit가 얼마나 발생했는지에 따른 hit ratio에 따라 유효 메모리 접근 시간이 달라진다.
Memory Protection)
페이징 이용 시 보호 비트를 통해서 메모리를 보호해야 한다. 하드웨어적으로 유효-무효 비트를 각 프레임에 추가해 메모리 접근이 유효한지 아닌지 확인 가능하다. valid일 경우 이에 해당하는 페이지가 프로세스의 논리 주소 공간에 포함되어 있고 invalid일 경우 논리 주소 공간에 없으므로 잘못된 접근이다. 잘못된 접근의 경우 인터럽터를 걸어버린다.
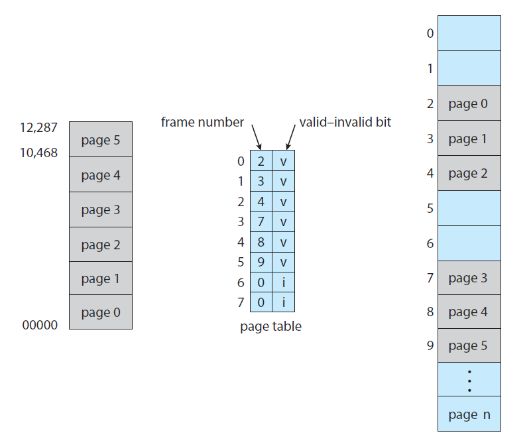
위 그림에서 0~5번 까지는 valid 한 영역이고 6,7번은 invalid 하다. 따라서 invalid 한 영역에 접근하고자 할 때는 잘못된 접근으로 인식하여 인터럽트를 건다.
Shared Page를 사용하면 DLL과 같이 공동으로 사용하는 코드를 공유할 수 있다. 이는 멀티프로그래밍 환경에서 중요하다.
이러한 라이브러리들을 각각 복사해서 쓴다면 매우 비효율적이다. 따라서 재진입 가능 코드(Reenturant Code)라면 프로세스 간에 공유하는 것이 유리하다.
<Segmentation>
세그멘테이션은 논리적 내용 기반으로 나눠서 메모리에 배치하는 것을 의미한다.
세그멘티에션을 할당하는 테이블을 세그먼트 테이블이라고 한다.
세그먼트 테이블은 세그먼트 번호, 시작 주소(base), 세그먼트 크기(limit)를 엔트리로 갖는다.
세그먼트는 크기가 일정하지 않다. 따라서 세그먼트의 크기를 넘어서는 주소가 들어오면 인터럽트가 발생해 해당 프로세스를 강제 종료시킨다.
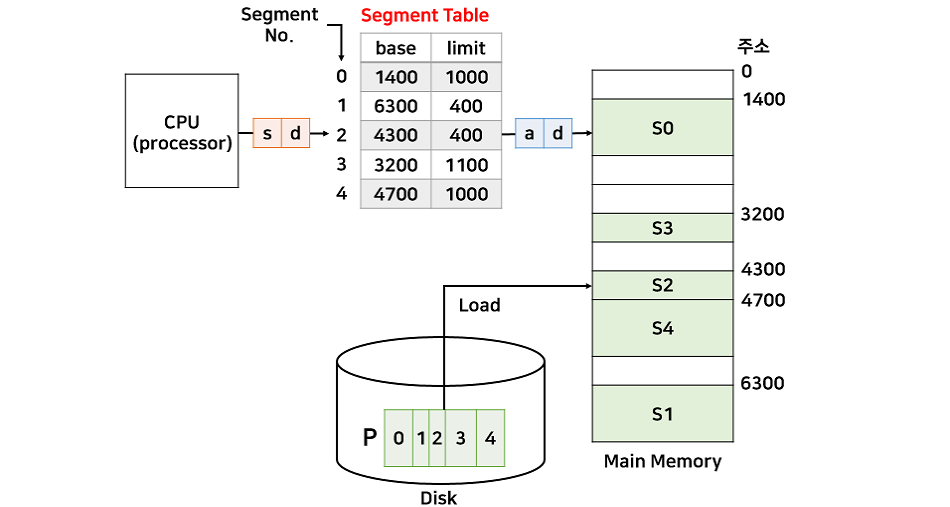
위 그림은 세그먼트 테이블과 프로세스가 할당된 메모리 모습인데, 페이징 주소변환가 동일하게 d는 논리 주소와 물리 주소가 동일하다.
a는 base [s] + d이다.
- 논리 주소 (2, 100) => 물리주소 4400번지 ==> base[2] = 4300, 4300+100 = 4400
- 논리주소 (1, 500) => 인터럽트로 인해 프로세스 강제 종료(범위를 벗어남) ==> base [1] = 6300, 6300+500=6800, out of range
Protection)
먼저, 결론부터 말하면 페이징보다 세그먼테이션에서의 보호와 공유는 더 효율적이다.
보호에서는 세그먼테이션 역시 r, w, x 비트를 테이블에 추가하는데, 세그먼테이션은 논리적으로 나누기 때문에 해당 비트를 설정하기 매우 간단하고 안전하다. 페이징은 code + data + stack 영역이 있을 때 이를 일정한 크기로 나누므로 두 가지 영역이 섞일 수가 있다. 그러면 비트를 설정하기가 매우 까다롭다.(페이징은 불연속적으로 동일한 크기로 쪼개기 때문에 어디서 끊길지 모른다.)
공유에서도 마찬가지다. 페이징에서는 code 영역을 나눈다 해도 다른 영역이 포함될 확률이 매우 높다. 하지만 세그먼테이션은 정확히 code 영역만 나누기 때문에 더 효율적으로 공유를 수행할 수 있다.
BUT...)
현재는 대부분 Paging 기법을 사용한다.
세그멘테이션 기법에는 치명적인 단점이 있다.
세그먼트의 크기는 일정하지 않고 다양하기에 hole의 크기가 다양하게 발생한다.
이에 대해서 제대로 된 hole에 프로세스를 할당하는 최적화 알고리즘의 부재로 인해서 그렇다.
결론적으로 세그먼테이션은 보호와 공유에서 효율적이고, 페이징은 외부 단편화 문제를 해결할 수 있다. 그러므로 두 가지를 합쳐서 사용하는 방법이 나왔다. 두 장점을 합치기 위해서는 세그먼트를 페이징 기법으로 나누는 것이다.(Paged segmentation)
하지만 이 역시 단점이 존재한다.
세그먼트와 페이지가 동시에 존재하기 때문에 주소 변환도 두 번해야 한다. 즉 CPU에서 세그먼트 테이블에서 주소 변환을 하고, 그 다음 페이지 테이블에서 또 주소 변환을 해야한다
'Computer Science > 운영체제' 카테고리의 다른 글
| Chapter 10. Virtual Memory (0) | 2022.06.10 |
|---|---|
| Chapter 08. Deadlocks (0) | 2022.06.03 |
| Chapter 07-2. Windows API (0) | 2022.06.02 |
| Chapter 07-1. Synchronization Examples (0) | 2022.06.02 |
| Chapter 06. Synchronization Tools (0) | 2022.06.01 |



