현재 연구실 프로젝트로 cilium hubble을 이용해서 네트워크 플로우 데이터를 수집하고 해당 데이터를 사용해서 Anomaly Detection을 수행하는 모델을 만들고 있다. Anomaly detection은 대다수의 정상 데이터들과 다른 양상을 보이는 희귀한 케이스를 탐지하는 걸 목표로 하는 Machine Learning의 연구분야 중 하나이다.
Anomaly Detection은 데이터 자체가 굉장히 imbalanced 하다. 이상 신호가 빈번하게 발생하면 그것은 이상 신호가 아니다.
또한 데이터의 양이 굉장히 많기 때문에 지도학습이 아닌 비지도 학습으로 접근하는 경우가 많다.
Isolation Forest 모델은 computational cost가 linear 하다고 한다. 즉 데이터의 양에 비례해서 일차함수 모양으로 cost가 증가한다는 것이다. 또한 anomaly detection에 특히 좋은 성능을 나타낸다고 제작자는 주장한다.
Isolation Forest의 동작 원리는 다음과 같다.
우선 Isolation 이란것 자체가 고립을 의미한다.
따라서 모델은 랜덤으로 특성을 선택하고 선택된 특성의 최댓값과 최솟값 사이의 분할값을 랜덤으로 선택해서 입력데이터를 격리하는 방식으로 작동한다. 해당 알고리즘은 더 작은 파티션으로 데이터를 재귀적으로 분할한다. 입력된 데이터가 자신의 파티션이 격리될 때까지 분할한다. 이때 데이터를 분할하는데 필요한 분할 횟수를 "path length"라고 한다. path length가 작은 경우 이상 신호일 확률이 높다. 입력된 데이터의 path length를 학습된 전체 데이터의 path length의 평균과 비교해서 경로가 짧은 데이터는 이상탐지로 판별한다.
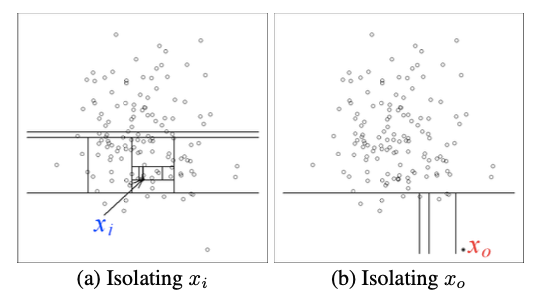
이때는 의사 결정 트리(Decison Tree)를 이용한다.
원래 데이터셋에 대해 bootstrapping without replacement 를 하여 여러 개의 sub-sample 들을 만든다.
sub-sample들을 이용해 각각의 iTree를 sub-dataset 개수만큼 build up 한다.
이렇게 만들어진 iTree들을 모두 모아 (ensemble) iForest를 도출한다.iForest에 있는 각각의 iTree를 이용해 i번째 데이터 포인트가 terminal node까지 분류되는데 소요된 split의 개수 혹은 root node에서부터 terminal node까지의 거리 (path length)를 계산한다.
<정리> 랜덤 추출된 특성을 바탕으로 선을그어서 데이터를 이분법 방식으로 나눠간다.(고립시켜 간다.) 더 이상 고립될 곳이 없으면 선을 몇 번 그었는지 세어본다.전체 데이터의 평균 선긋기 횟수보다 적으면 이상탐지일 확률이 높다.
출처: https://woodyahn.tistory.com/60
[Anomaly Detection] Isolation Forest 설명
목차 Introduction Anomaly detection 이란? Anomaly detection은 대다수의 정상 데이터들과 다른 양상을 보이는 희귀한 케이스를 탐지하는 걸 목표로 하는 Machine Learning의 연구분야 중 하나입니다. Anomaly detecti
woodyahn.tistory.com
'AI & Data Science' 카테고리의 다른 글
| IoT 중간고사 정리 (0) | 2023.04.18 |
|---|---|
| CNN (0) | 2023.04.01 |
| 2022 제4회 매치업 스마트시티 아이디어톤(AI 서비스 부문) 후기 (장려상 수상) (0) | 2022.12.26 |
| 2022년 제 1회 k-ium 의료 인공지능 경진대회 후기(최우수상 수상) (0) | 2022.10.30 |
| BoostCourse AI Pre-Course) RNN(Recurrent Neural Network) (0) | 2022.08.03 |



